Get 69% Off on Cloud Hosting : Claim Your Offer Now!
- Products
- Solutions
-
Solutions
-
 Cloud
Hosting
Cloud
Hosting
-
VPS
Hosting
-
 GPU
Cloud
GPU
Cloud
-
 Dedicated
Server
Dedicated
Server
-
 Server
Colocation
Server
Colocation
-
 Backup as a Service
Backup as a Service
-
 CDN
Network
CDN
Network
-
 Window
Cloud Hosting
Window
Cloud Hosting
-
 Linux
Cloud Hosting
Linux
Cloud Hosting
-
Managed
Cloud Service
-
 Storage
as a Service
Storage
as a Service
-
VMware
Public Cloud
-
Multi-Cloud
Hosting
-
Cloud
Server Hosting
-
Bare
Metal Server
-
Virtual
Machine
-
 Magento
Hosting
Magento
Hosting
-
 Remote
Backup
Remote
Backup
-
 DevOps
DevOps
-
 Kubernetes
Kubernetes
-
 Cloud
Storage
Cloud
Storage
-
 NVMe
Hosting
NVMe
Hosting
-
 DR
as s Service
DR
as s Service
-
-
Solutions
- Marketplace
- Pricing
- Resources
- Company
 Pricing
Calculator
Pricing
Calculator
 Power
Power
 Utilities
Utilities VMware
Private Cloud
VMware
Private Cloud VMware
on AWS
VMware
on AWS VMware
on Azure
VMware
on Azure Service
Level Agreement
Service
Level Agreement Table of Contents
- The Heat Is On — And AI Is Turning It Up
- Why Air Cooling Simply Cannot Keep Up
- How Liquid Cooling Actually Works: A Technical Breakdown
- The Market Has Spoken: Liquid Cooling Is a $27 Billion Opportunity
- Cyfuture Cloud: India’s Answer to the Global AI Infrastructure Demand
- Who Needs to Pay Attention Right Now?
- What Is Coming Next: The Cooling Frontier in 2026 and Beyond
- The Bottom Line
The Heat Is On — And AI Is Turning It Up
Here’s the uncomfortable truth no one in the data center industry wants to say out loud: we built the internet on fans and cold air, and AI just blew that model apart.
In 2026, training a frontier AI model — a large language model (LLM), a generative video system, a multi-modal foundation model — requires rack densities that were considered science fiction just four years ago. NVIDIA’s GB200 NVL72, the reference architecture for serious AI training, draws 120–132 kW per rack under full load. For context, most data centers built before 2022 were designed for 15–30 kW per rack. That is a 5–8x gap that no amount of airflow engineering can bridge.
And it is only going to get more extreme. NVIDIA’s next-generation Vera Rubin NVL144 targets approximately 600 kW per rack. Deloitte estimates that next-generation AI racks could reach 370 kW even in 2026. There is no fan in existence — and no cold aisle — that solves 370 kW. Liquid cooling is not the future of AI infrastructure. It is the present.

Why Air Cooling Simply Cannot Keep Up
Let’s break this down so it is crystal clear. Imagine trying to cool a blast furnace with a household desk fan. That is essentially what operators are attempting when they deploy next-generation NVIDIA GPUs — AI accelerators with heat flux densities of 500–600 W/cm² — in legacy air-cooled data centers.
Removing 100 kW of heat through airflow alone would require moving 35,000 cubic feet of air per minute through the cold aisle. That level of airflow makes structured cabling, hardware access, and basic maintenance practically impossible. It also makes energy bills catastrophic.
The PUE Problem
PUE (Power Usage Effectiveness) is the standard metric for data center efficiency. A PUE of 1.0 is perfect — every watt goes to compute. Traditional air-cooled data centers hover between 1.4 and 1.6 PUE, meaning 40–60% of electricity consumed is wasted on cooling alone.
|
Cooling Method |
Typical PUE |
Max Rack Density |
|
Traditional Air Cooling |
1.4–1.6 |
15–35 kW/rack |
|
Hybrid (Air + Liquid) |
1.2–1.4 |
40–80 kW/rack |
|
Direct-to-Chip (DLC) |
1.05–1.15 |
60–132 kW/rack |
|
Full Immersion Cooling |
1.02–1.05 |
200+ kW/rack |
The EU already mandates PUE below 1.3 for new data centers by 2030. Singapore requires new facilities to hit PUE below 1.2. Regulations are arriving faster than most enterprise IT roadmaps. The operators who are building liquid-first today are not just being forward-thinking — they are being strategically compliant.
How Liquid Cooling Actually Works: A Technical Breakdown
So what exactly happens inside a liquid cooled AI data center? Here is the engineering, explained clearly.
Direct-to-Chip Cooling (DLC)
Cold plates — precision-engineered metal blocks with microchannels inside — are mounted directly onto the surfaces of GPUs and CPUs. A coolant (usually deionized water with corrosion inhibitors, or a glycol mixture) circulates through these channels, absorbing heat at the source. This coolant then flows to a Coolant Distribution Unit (CDU), where a heat exchanger transfers the heat to a facility chilled water loop. The chilled coolant is recirculated back to the chip.
DLC systems handle 60–100 kW per rack reliably and are the standard for current-generation AI training clusters. The NVIDIA GB200 NVL72’s integrated DLC system requires coolant flow exceeding 700 litres per minute at the rack manifold — a demand that most retrofitted legacy facilities simply cannot meet without significant mechanical upgrades.
Immersion Cooling
In immersion cooling, entire server boards are submerged in a non-conductive dielectric fluid. Heat transfers directly from components to the fluid, which is then recirculated through a heat exchanger. Single-phase immersion keeps the fluid in liquid form throughout, while two-phase immersion allows the fluid to vaporize and recondense — achieving even greater heat transfer efficiency. Immersion cooling delivers PUE values between 1.02 and 1.05, reduces electricity demand by up to nearly 50% compared to air cooling, and supports 99% less water consumption than traditional evaporative cooling systems.
The Market Has Spoken: Liquid Cooling Is a $27 Billion Opportunity
The numbers are unambiguous. The global data center liquid cooling market was valued at USD 4.8 billion in 2025 and is projected to reach USD 27.1 billion by 2035, growing at a CAGR of 18.2% (Global Market Insights). A separate analysis puts the broader AI data center liquid cooling infrastructure market at $6.8 billion in 2025, expanding to $56.2 billion by 2034 at a 26.4% CAGR.
Goldman Sachs projects that 76% of AI servers deployed by end of 2026 will require liquid cooling — up from just 15% in 2024. That 61-percentage-point swing in two years is not a trend. It is a structural transformation.
Hyperscalers are leading the charge. Microsoft mandated direct-to-chip liquid cooling for all new Azure AI server deployments in early 2025. Oracle’s newest AI campuses deploy closed-loop non-evaporative cooling systems. Google’s Project Deschutes implements liquid cooling for its TPU hardware. These are not pilot projects. They are fleet-level commitments from companies spending hundreds of billions on AI infrastructure.
Cyfuture Cloud: India’s Answer to the Global AI Infrastructure Demand
Here is where it gets exciting for Indian enterprises, AI startups, and sovereign AI initiatives.
Cyfuture Cloud has announced India’s premier 10MW Direct-to-Chip Liquid Cooled AI Data Center, purpose-built for large-scale AI workloads including LLM training, AI inference, generative AI, and sovereign AI deployments. The facility is scheduled to go live on 31 October 2026.
This is not a conventional data center with a cooling upgrade. It is designed liquid-first — which means every design decision, from the building’s mechanical plant to the network topology, is optimized for the thermal and power demands of next-generation GPU clusters.
What Makes This Facility Different
- 10MW direct-to-chip liquid cooling capacity — purpose-built, not retrofitted
- Support for NVIDIA GPU clusters (H100, H200, Blackwell architecture) and next-generation AI accelerators
- Designed for LLM training, generative AI, AI inference, and sovereign AI workloads
- Delivers 30–50% higher energy efficiency versus air-cooled alternatives
- Serves enterprises, hyperscalers, cloud providers, and government organizations
- Backed by Cyfuture’s existing Tier III certified, MeitY Empanelled data center network across Noida, Jaipur, Raipur, and Bangalore with 99.982% uptime guarantee
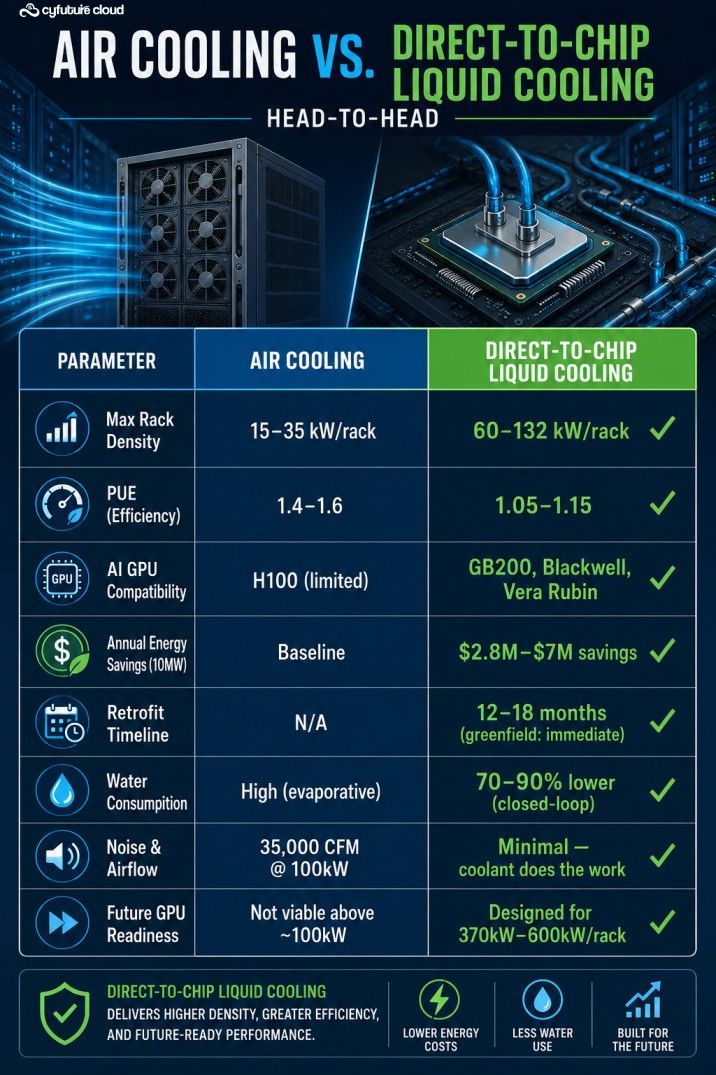
Who Needs to Pay Attention Right Now?
This is not just a topic for data center architects. The implications of the liquid cooling transition ripple across every layer of the AI value chain.
For Enterprises Building or Scaling AI
If your AI roadmap involves training models larger than 7B parameters, running real-time inference at scale, or deploying GPU clusters of more than 10 nodes, your infrastructure decisions made today will determine your competitive position in 2027. Air-cooled colocation cannot support your next GPU generation. Start evaluating liquid-cooled options now — not when the GB200 allocation arrives and you have nowhere to plug it in.
For Cloud Architects and CTOs
The colocation and cloud markets are bifurcating. Liquid-cooled AI infrastructure commands a premium — but it is the only infrastructure that can run the hardware your teams are requesting. A 10MW liquid-cooled facility like Cyfuture Cloud’s is not a cost center; it is a capability enabler.
For Students and AI Researchers
Understanding thermal constraints is increasingly a core competency for anyone designing distributed AI systems. The GPU you train on, the latency you achieve, the batch size you can run — all of these are downstream consequences of whether the facility housing your cluster can actually cool it. Liquid cooling is not just a facilities concern; it is a systems design constraint.
For Government and Sovereign AI Initiatives
Sovereign AI — training national models on domestic infrastructure, keeping sensitive data within borders — requires the kind of high-density, high-reliability facility that liquid cooling enables. Without domestic liquid-cooled AI infrastructure, sovereign AI is a policy aspiration without an engineering foundation.
What Is Coming Next: The Cooling Frontier in 2026 and Beyond
The liquid cooling market is not standing still. Several developments in 2026 signal where the industry is heading:
- CoolIT Systems demonstrated a 15kW single cold plate in June 2026 — nearly four times the capacity of its previous design — targeting ultra-high-density GPUs and future AI accelerators.
- Motivair (Schneider Electric) introduced the MCDU-70, a 2.5MW coolant distribution unit designed for next-generation AI factories, with its CDU portfolio scalable to 10MW and beyond.
- Major M&A activity is consolidating the sector: Ecolab acquired CoolIT Systems, Trane Technologies acquired LiquidStack, and Eaton acquired Boyd Corporation for $9.5 billion — signaling that cooling infrastructure has become a strategic asset class.
- Microsoft is actively developing microfluidic cooling — channels etched into chip packages, borrowing from biomedical engineering — targeting the GPU generations beyond Blackwell.
- NVIDIA’s Vera Rubin Ultra configurations, targeting 600 kW per rack, will require cooling infrastructure that has no widely deployed commercial analogue today. Facilities being designed now must account for this density.
The operators investing in liquid-cooled infrastructure today — including Cyfuture Cloud — are not just solving 2026’s problems. They are building the foundation for AI compute that will not even be announced for another two years.

The Bottom Line
The AI revolution runs on chips. Chips run on power. Power generates heat. And heat — at the scale AI now demands — requires liquid cooling. This is not a debate about whether liquid cooling will become the standard for AI infrastructure. That debate ended when NVIDIA shipped the GB200 NVL72.
The debate now is about who builds liquid-cooled AI infrastructure, where, and for whom. In India, Cyfuture Cloud is answering that question with a 10MW direct-to-chip liquid cooled facility that will go live October 31, 2026 — giving Indian enterprises, cloud providers, and sovereign AI initiatives access to the kind of infrastructure that was previously only available from global hyperscalers in foreign jurisdictions.
The next AI revolution will not be powered by faster chips alone. It will be powered by the infrastructure smart enough to keep those chips cool.





















Stay Ahead of the Curve.
Join the Cloud Movement, today!
Send this to a friend