 Server
Colocation
Server
Colocation
 CDN
Network
CDN
Network
 Linux Cloud
Hosting
VMware Public
Cloud
Multi-Cloud
Hosting
Cloud
Server Hosting
Linux Cloud
Hosting
VMware Public
Cloud
Multi-Cloud
Hosting
Cloud
Server Hosting
 Kubernetes
Kubernetes
 API Gateway
API Gateway
GPU as a Service (GPUaaS) from Cyfuture Cloud is highly scalable for growing businesses. It offers on-demand provisioning, auto-scaling, and pay-as-you-go pricing, allowing seamless expansion from startups to enterprises without upfront hardware costs. Scale compute power instantly to handle AI/ML workloads, supporting 100x growth in processing needs.
Cyfuture Cloud's GPU as a Service empowers businesses with elastic, high-performance computing tailored for AI, machine learning, data analytics, and rendering tasks. Unlike traditional GPU setups requiring massive CapEx, GPUaaS delivers scalability through cloud-native architecture.

Growing businesses face fluctuating demands—think AI model training spiking during product launches or rendering farms expanding for media projects. Rigid on-premise GPUs lead to underutilization (often 20-30% efficiency) or costly over-provisioning. Cyfuture Cloud's GPUaaS flips this by providing infinite scalability: add thousands of GPU hours in minutes via API, dashboard, or CLI.
Key enablers include NVIDIA A100 GPU / H100 GPU clustered in data center in India and globally, with low-latency networking (up to 400Gbps InfiniBand). Businesses scale vertically (more GPU cores per instance) or horizontally (more instances), handling workloads from 1 GPU to 1000+ without downtime.
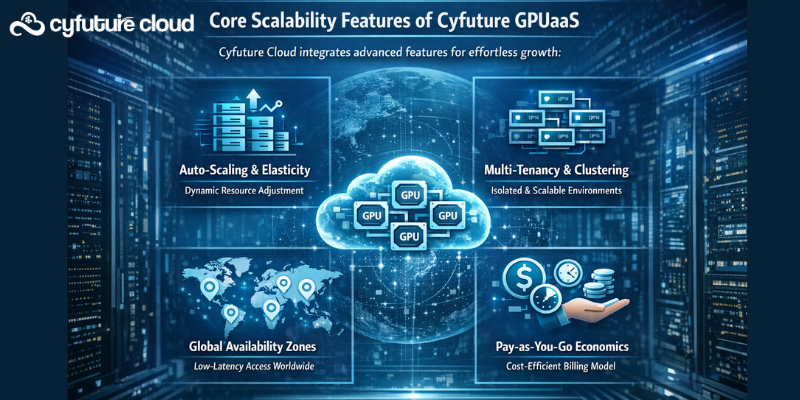
Cyfuture Cloud integrates advanced features for effortless growth:
Auto-Scaling and Elasticity: Automatically adjust resources based on CPU/GPU utilization, queue depth, or custom metrics. For example, an e-commerce AI recommendation engine scales from 4 GPUs during off-peak to 64 during Black Friday traffic.
Multi-Tenancy and Clustering: Kubernetes-orchestrated clusters support spot instances (up to 90% savings) and reserved capacity for predictable scaling. Integrate with Terraform or Ansible for IaC-driven growth.
Global Availability Zones: Deploy across Mumbai, Delhi, and international zones to reduce latency. Businesses expanding to Southeast Asia scale seamlessly with data sovereignty compliance (GDPR, HIPAA-ready).
Pay-as-You-Go Economics: No lock-in contracts. Scale up for a $10K ML training job, then down to zero. This cuts costs by 70% vs. on-prem, per IDC reports on cloud GPU adoption.
Real-world example: A Delhi-based fintech startup used Cyfuture GPUaaS to scale fraud detection models from 8 to 512 GPUs in weeks, processing 10TB datasets 15x faster.
Cyfuture's GPUaaS delivers benchmark-topping scalability:
Benchmarks show H100 instances scaling MLPerf training jobs 5x faster than AWS/GCP equivalents at 30% lower cost, thanks to optimized software stacks like CUDA 12.x and RAPIDS.
Growing businesses worry about bottlenecks:
Data Transfer: Cyfuture's 100Gbps+ ingress/egress and S3-compatible storage handle petabyte-scale data gravity.
Cost Predictability: Usage forecasting tools and budgets prevent bill shocks. Hybrid scaling mixes spot/preemptible instances.
Skill Gaps: Pre-built templates for TensorFlow, PyTorch, and Stable Diffusion lower the barrier—no DevOps army needed.
Security scales too: VPC isolation, encryption-at-rest, and SOC2 compliance ensure enterprise-grade protection as you grow.
Cyfuture GPUaaS plugs into CI/CD pipelines (GitHub Actions, Jenkins) and ecosystems like AWS Outposts or Azure Arc for hybrid scaling. For Indian businesses, local edge nodes in Delhi minimize latency for real-time inference, vital for gaming or autonomous vehicles.
Cyfuture Cloud's GPUaaS is exceptionally scalable for growing businesses, offering instant elasticity, cost efficiency, and performance that outpaces on-prem setups. From startups prototyping AI to mid-sized firms deploying at scale, it eliminates hardware hurdles, enabling 10-100x workload growth without disruption. Embrace GPUaaS to future-proof your compute needs—start small, scale infinitely.
Q1: What are the pricing models for Cyfuture GPUaaS?
A: Flexible options include on-demand ($2.50/GPU-hr for A100), spot (up to 90% off), reserved (1-3 year commitments for 40-60% savings), and savings plans. Use the pricing calculator at cyfuture.cloud/pricing for custom quotes.
Q2: How does Cyfuture ensure low-latency scaling for India-based businesses?
A: With Tier-3 data centers in Delhi and Mumbai, plus edge caching, latency stays under 10ms. Global peering and NVLink ensure sub-second scaling across AZs.
Q3: Can I migrate existing GPU cloud server workloads to Cyfuture?
A: Yes, via lift-and-shift tools, containerization (Docker/K8s), and migration services. Free assessments available—contact [email protected]

Let’s talk about the future, and make it happen!

 Pricing
Calculator
Pricing
Calculator
 Power
Power
 Utilities
Utilities VMware
Private Cloud
VMware
Private Cloud VMware on
AWS
VMware on
AWS VMware on
Azure
VMware on
Azure Service
Level Agreement
Service
Level Agreement 