 Server
Colocation
Server
Colocation
 CDN
Network
CDN
Network
 Linux Cloud
Hosting
VMware Public
Cloud
Multi-Cloud
Hosting
Cloud
Server Hosting
Linux Cloud
Hosting
VMware Public
Cloud
Multi-Cloud
Hosting
Cloud
Server Hosting
 Kubernetes
Kubernetes
 API Gateway
API Gateway
The NVIDIA H200 GPU differs from the H100 GPU primarily through its expanded HBM3e memory capacity (141 GB vs. 80 GB HBM3), higher memory bandwidth (4.8 TB/s vs. 3.35 TB/s), and improved efficiency for large-scale compute workloads. Both GPUs are built on NVIDIA’s Hopper architecture and share similar peak compute capabilities, but the H200 is designed to handle significantly larger datasets without memory bottlenecks.
On Cyfuture Cloud, the H200 gpu delivers up to 45% better performance for large-model processing and supports higher throughput for memory-intensive workloads. The H100 remains a strong option for mid-scale workloads and cost-sensitive deployments. Both the H100 GPU and H200 GPU are available through Cyfuture Cloud’s GPU as a Service, offering flexible enterprise-grade hosting plans.
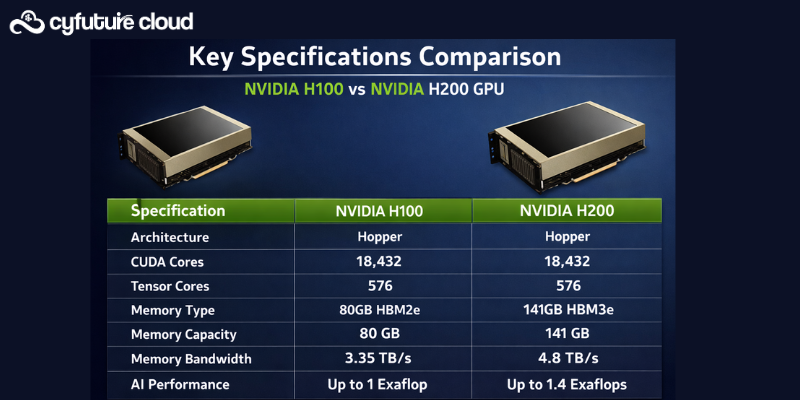
Cyfuture Cloud users can deploy both H100 and H200 GPUs in optimized cloud environments. The H100 GPU features 80 GB HBM3 memory with 3.35 TB/s bandwidth, enabling strong performance in deep learning and high-performance computing workloads, reaching up to 3,026 TFLOPS in FP8 Tensor Core operations.
In contrast, the H200 GPU increases memory capacity to 141 GB using HBM3e technology and boosts bandwidth to 4.8 TB/s, representing nearly 1.4× higher throughput. This improvement allows faster processing of complex simulations and large models such as LLaMA-2 70B, reducing reliance on memory swapping.
Both GPUs support Multi-Instance GPU (MIG) partitioning, confidential computing, and up to 7 NVDEC decoders. The H200 supports MIG slices of up to 16.5–18 GB, compared to approximately 10–12 GB on the H100. Power configurations scale up to 700W for H200 SXM variants and 600W for H100 SXM.
Cyfuture Cloud integrates these GPUs using NVLink (900 GB/s) for multi-GPU scaling, paired with AMD EPYC or Intel Xeon processors and up to 2 TB DDR5 RAM per node. Performance testing shows up to 2× faster inference speeds and major acceleration gains in simulation-driven workloads, with 17–45% improvements over H100 GPU deployments in real-world benchmarks.
Despite the higher power envelope, the H200 GPU delivers better efficiency due to refined Tensor Cores and enhanced Transformer Engine optimizations. This enables faster execution on large datasets while controlling operational costs for Cyfuture Cloud users.
Cyfuture Cloud positions the H200 GPU as the preferred choice for workloads requiring maximum memory capacity and bandwidth, while the H100 GPU remains a reliable and cost-effective option for moderate-scale deployments. By offering both through GPU as a Service, Cyfuture Cloud allows enterprises to scale without capital expenditure, supported by high-availability infrastructure and 24/7 technical assistance.
A: Choose H200 for large-scale LLM fine-tuning due to its 141GB HBM3e memory, which handles massive models without bottlenecks. H100 is suitable for smaller LLMs but may require multiple instances.
A: H200 is typically priced 25–50% higher than H100 due to enhanced specs. Cyfuture Cloud offers flexible on-demand and custom pricing, helping reduce total cost of ownership (TCO).
A: Yes. Cyfuture Cloud supports 1,000+ node H200 clusters with NVLink, DCGM monitoring, and rapid provisioning for AI/ML workloads.
A: Yes. Built on NVIDIA’s Hopper architecture, H200 is fully compatible with H100 software. Cyfuture Cloud pre-configures popular AI frameworks for seamless migration.
A: The NVIDIA H200 is a high-performance data-center GPU designed for AI training, inference, and HPC, featuring ultra-high memory bandwidth and capacity.
A: Enterprise pricing varies by region and volume, but H200 chips are estimated to cost significantly more than H100 due to advanced memory and performance.
A: Due to export regulations, direct sales of H200 to China are restricted, similar to other advanced NVIDIA AI GPUs.
A: No. H200 is built for data center in India and AI workloads, not gaming. Consumer GPUs like RTX series are better suited for gaming.
A: Yes. H200 offers higher memory (141GB vs 80GB) and faster bandwidth, making it better for large AI models and memory-intensive workloads.
A: Yes. H200 is one of NVIDIA’s most advanced AI accelerators, optimized for next-generation LLMs and HPC tasks.
A: For AI and data centers, NVIDIA H200/H100 lead the market. For consumers, top RTX cards lead gaming performance.
A: NVIDIA has seen massive growth driven by AI demand; a $10,000 investment five years ago would be worth significantly more today, depending on entry date.
A: Yes. The RTX 6000 Ada Generation is a professional workstation GPU used for design, AI, and rendering.
A: Pricing varies based on deployment and usage. On Cyfuture Cloud, H200 pricing is offered via custom and on-demand plans for Indian enterprises.
A: NVIDIA H100 gpu comes with 80GB HBM3 memory.
A: Sales of standard H100 GPUs to China are restricted under export controls.
A: H200 features over 14,000 CUDA cores, similar to H100, with major gains coming from memory upgrades.
A: B100 is an upcoming NVIDIA GPU based on the Blackwell architecture, designed to surpass Hopper-based GPUs.
A: H200 is Hopper-based, while GB200 combines Blackwell GPUs with Grace CPUs, offering next-level performance for AI supercomputing.
A: Large-scale models like ChatGPT are trained on NVIDIA data-center GPUs, including A100, H100, and newer architectures.
A: Currently, NVIDIA’s H200 and upcoming Blackwell GPUs are among the fastest for AI workloads.
A: H200 is based on the Hopper architecture, not Blackwell.

Let’s talk about the future, and make it happen!

 Pricing
Calculator
Pricing
Calculator
 Power
Power
 Utilities
Utilities VMware
Private Cloud
VMware
Private Cloud VMware on
AWS
VMware on
AWS VMware on
Azure
VMware on
Azure Service
Level Agreement
Service
Level Agreement 