Get 69% Off on Cloud Hosting : Claim Your Offer Now!
- Products
- Solutions
-
Solutions
-
 Cloud
Hosting
Cloud
Hosting
-
VPS
Hosting
-
 GPU
Cloud
GPU
Cloud
-
 Dedicated
Server
Dedicated
Server
-
 Server
Colocation
Server
Colocation
-
 Backup as a Service
Backup as a Service
-
 CDN
Network
CDN
Network
-
 Window
Cloud Hosting
Window
Cloud Hosting
-
 Linux
Cloud Hosting
Linux
Cloud Hosting
-
Managed
Cloud Service
-
 Storage
as a Service
Storage
as a Service
-
VMware
Public Cloud
-
Multi-Cloud
Hosting
-
Cloud
Server Hosting
-
Bare
Metal Server
-
Virtual
Machine
-
 Magento
Hosting
Magento
Hosting
-
 Remote
Backup
Remote
Backup
-
 DevOps
DevOps
-
 Kubernetes
Kubernetes
-
 Cloud
Storage
Cloud
Storage
-
 NVMe
Hosting
NVMe
Hosting
-
 DR
as s Service
DR
as s Service
-
-
Solutions
- Marketplace
- Pricing
- Resources
- Company
 Pricing
Calculator
Pricing
Calculator
 Power
Power
 Utilities
Utilities VMware
Private Cloud
VMware
Private Cloud VMware
on AWS
VMware
on AWS VMware
on Azure
VMware
on Azure Service
Level Agreement
Service
Level Agreement Table of Contents
- The Hopper Architecture: A Quantum Leap in AI Performance
- Revolutionary Transformer Engine: Purpose-Built for Modern AI
- Unmatched Speed: Redefining AI Performance Benchmarks
- Extreme Memory Bandwidth: Eliminating Data Bottlenecks
- Advanced Scalability: Building AI Supercomputers
- Multi-Instance GPU Technology: Maximizing Efficiency
- Power Efficiency: Performance That Makes Economic Sense
- Why Cyfuture Cloud for Your H100 Deployment
- The Future of AI Starts Now
- Frequently Asked Questions
- What makes the H100 GPU better than the A100 for AI workloads?
- Can Cyfuture Cloud’s H100 servers handle training large language models like GPT-4?
- How does Multi-Instance GPU (MIG) technology benefit our AI development team?
- What is the cost advantage of using H100 servers for AI training?
- Does Cyfuture Cloud provide support for optimizing AI workloads on H100 infrastructure?
The artificial intelligence revolution is accelerating at an unprecedented pace, and the computational demands of modern AI workloads have never been more intense. From training massive language models with billions of parameters to deploying real-time inference systems, organizations need infrastructure that can keep pace with innovation. Enter the NVIDIA H100 GPU server—the gold standard for AI and deep learning infrastructure that’s transforming how enterprises approach machine learning at scale.

The Hopper Architecture: A Quantum Leap in AI Performance
NVIDIA H100 GPU servers are considered the premier choice for AI and deep learning, particularly for training and deploying large language models (LLMs), because they are designed specifically for the massive parallel processing, high-speed memory bandwidth, and transformer-based architectures required by modern artificial intelligence. Built on the revolutionary Hopper architecture, these servers provide a massive performance leap over previous generations, offering up to 9x faster training and 30x higher inference throughput for large models.
This isn’t just an incremental improvement—it’s a fundamental shift in what’s possible with AI infrastructure. Organizations that once measured model training time in weeks can now complete the same tasks in days or even hours, dramatically accelerating their time to market and competitive advantage.

Revolutionary Transformer Engine: Purpose-Built for Modern AI
At the heart of the H100’s dominance in AI workloads lies its dedicated Transformer Engine, a breakthrough innovation specifically optimized for the transformer-based architectures that power today’s most advanced AI systems. The Transformer Engine uses fourth-generation Tensor Cores to intelligently accelerate models like GPT, BERT, and other generative AI foundations by dynamically switching between FP8 and FP16 precision during computation.
This dynamic precision management isn’t just clever engineering—it’s a game-changer for practical AI deployment. By utilizing FP8 precision, H100 servers reduce memory usage by up to 75% while maintaining model accuracy, allowing for significantly faster training and inference. This means organizations can train larger models, process more data, and deploy more sophisticated AI applications without compromising on quality or performance.
Unmatched Speed: Redefining AI Performance Benchmarks
The H100 delivers computational power that eclipses its predecessors in every meaningful metric. Offering up to 4x higher AI training performance for large models like GPT-3 compared to the A100 gpu, the H100 transforms training workflows that once seemed impossibly time-consuming into manageable, iterative processes.
But perhaps even more impressive is the inference performance—the H100 delivers up to 30x higher inference performance for large models, which is crucial for real-time applications where milliseconds matter. Whether you’re deploying conversational AI, recommendation engines, or computer vision systems, this inference leadership ensures your AI applications respond instantaneously to user queries.
The fourth-generation Tensor Cores accelerate all AI precisions, including FP64, TF32, FP16, and FP8, making them versatile for both cutting-edge research and production-grade deployments. This versatility means organizations don’t need separate infrastructure for different stages of their AI pipeline—the H100 handles everything from experimentation to production with equal excellence.
Extreme Memory Bandwidth: Eliminating Data Bottlenecks
Modern AI cloud models are data-hungry beasts, and memory bandwidth often becomes the limiting factor in training performance. The H100 addresses this challenge head-on with up to 80GB of HBM3 memory (in the SXM5 version) and an astounding 3.35 TB/s bandwidth. This extreme memory capacity and speed prevent data bottlenecks, allowing for the seamless processing of massive datasets and the training of models with hundreds of billions of parameters.
This high-speed memory architecture is essential for handling large models and complex AI computations without performance degradation. When your training dataset measures in terabytes and your model contains billions of parameters, the difference between adequate and exceptional memory performance can mean the difference between project success and failure.
Advanced Scalability: Building AI Supercomputers
Individual GPU performance matters, but modern AI demands scale. The H100’s fourth-generation NVLink provides 900 GB/s bidirectional bandwidth—7x faster than PCIe Gen5—enabling efficient communication across hundreds of GPUs in a cluster. This interconnect technology transforms clusters of H100 GPUs into unified supercomputers capable of tackling the most ambitious AI projects.
With NVLink, organizations can scale up to 256 H100 GPUs working together as a single cohesive unit, essential for training massive, trillion-parameter AI models that are pushing the boundaries of what artificial intelligence can achieve. This level of scalability means there’s virtually no AI project too large or complex for H100-powered infrastructure.
Multi-Instance GPU Technology: Maximizing Efficiency
In cloud environments where resource optimization directly impacts profitability, the H100’s second-generation Multi-Instance GPU (MIG) technology is a revelation. MIG allows a single H100 GPU to be partitioned into up to seven independent, isolated instances, ideal for maximizing utilization in shared, multi-tenant cloud environments.
This capability is particularly valuable for organizations running diverse AI workloads—development teams can share GPU resources without interference, research projects can run in isolation, and production inference services can operate with guaranteed performance. Additionally, built-in confidential computing features secure AI models and data in use, which is critical for regulated industries like finance and healthcare where data privacy isn’t negotiable.
Power Efficiency: Performance That Makes Economic Sense
While the H100 is a high-performance powerhouse consuming up to 700W, it delivers exceptional performance-per-watt compared to previous generations, making it more cost-effective for large-scale, long-term AI training tasks. When you calculate total cost of ownership—factoring in training time reduction, infrastructure consolidation, and energy costs—the H100 represents not just technical superiority but economic wisdom.
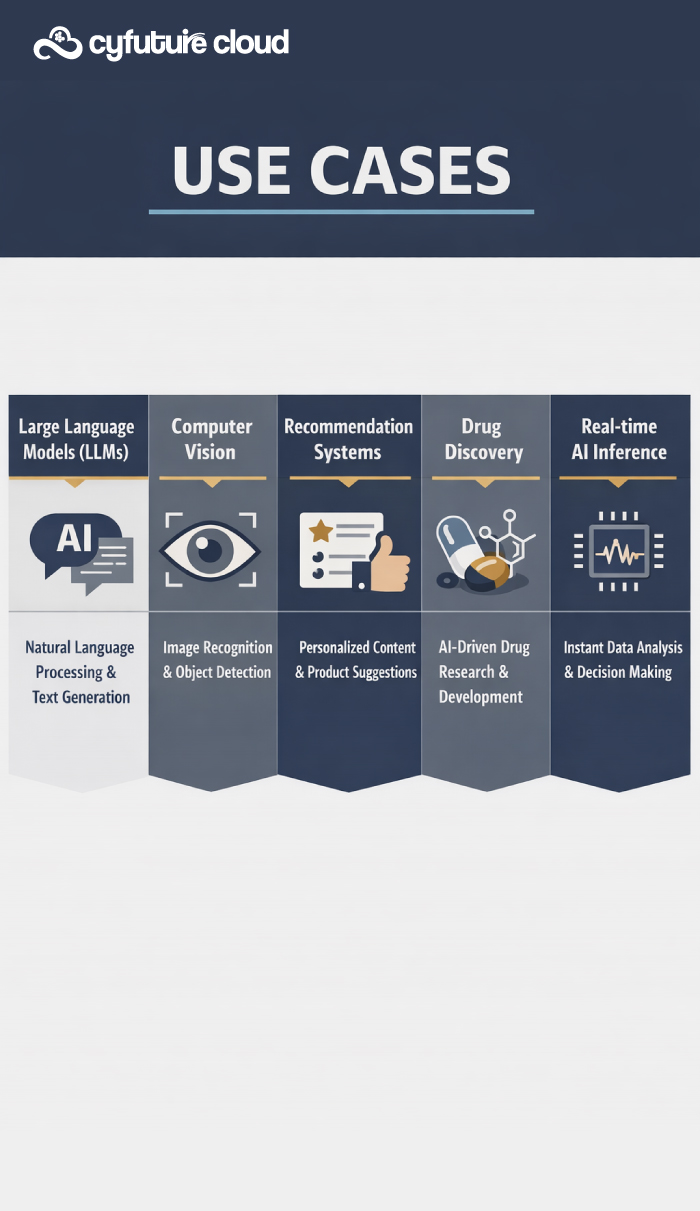
Why Cyfuture Cloud for Your H100 Deployment
At Cyfuture Cloud, we understand that access to cutting-edge hardware is only part of the equation. Our H100 GPU server offerings combine NVIDIA’s revolutionary technology with enterprise-grade infrastructure, 24/7 expert support, and flexible deployment options tailored to your specific AI workloads.
Whether you’re training the next breakthrough language model, developing computer vision systems, or deploying production AI services at scale, Cyfuture Cloud provides the reliable, high-performance infrastructure you need to turn AI ambitions into reality.
The Future of AI Starts Now
In summary, H100 servers are designed to reduce training times from months to days or hours, providing the essential cloud infrastructure for the next generation of AI breakthroughs. The combination of the Transformer Engine, unprecedented computational power, extreme memory bandwidth, advanced scalability, and intelligent resource management makes the H100 the definitive choice for serious AI development.
The AI revolution waits for no one, and the organizations that succeed will be those equipped with infrastructure that matches their ambitions. With H100 GPU cloud servers from Cyfuture Cloud, you’re not just keeping pace with AI innovation—you’re leading it.

Frequently Asked Questions
What makes the H100 GPU better than the A100 for AI workloads?
The H100 offers significant advantages over the A100, including up to 4x higher AI training performance for large models and up to 30x higher inference performance. Built on the newer Hopper architecture, it features a dedicated Transformer Engine optimized for modern LLMs, 80GB of faster HBM3 memory (vs. 80GB HBM2e in A100), and fourth-generation Tensor Cores that support FP8 precision. The H100 also provides 3x higher memory bandwidth and more advanced NVLink connectivity. For organizations training large language models or deploying production AI at scale, the H100 represents a generational leap in capabilities that directly translates to faster time-to-market and reduced operational costs.
Can Cyfuture Cloud’s H100 servers handle training large language models like GPT-4?
Absolutely. Cyfuture Cloud’s H100 GPU servers are specifically designed for training and deploying large language models with billions or even trillions of parameters. The combination of 80GB HBM3 memory per GPU, extreme memory bandwidth of 3.35 TB/s, and the ability to scale up to 256 interconnected H100 GPUs provides the infrastructure necessary for the most demanding LLM training tasks. The Transformer Engine’s FP8 precision support means you can train larger models more efficiently, while the advanced NVLink technology enables the multi-GPU coordination essential for distributed training of massive models. Whether you’re fine-tuning existing models or training custom LLMs from scratch, our H100 infrastructure delivers the performance you need.
How does Multi-Instance GPU (MIG) technology benefit our AI development team?
MIG technology allows a single H100 GPU to be partitioned into up to seven independent, fully isolated instances, each with dedicated memory and compute resources. This is particularly valuable for development teams running multiple projects simultaneously—different team members can work on separate models without interfering with each other’s work, you can run development, testing, and production workloads on the same physical hardware, and smaller inference workloads can utilize GPU resources efficiently without requiring a full GPU. For Cyfuture Cloud customers, this means better resource utilization, improved cost efficiency, and the flexibility to match GPU allocation precisely to workload requirements. It’s especially beneficial in multi-tenant environments where security isolation between workloads is critical.
What is the cost advantage of using H100 servers for AI training?
While H100 GPUs represent a premium hardware investment, they deliver substantial cost advantages through dramatically reduced training times and improved operational efficiency. Training that might take weeks on older infrastructure can be completed in days or even hours on H100 servers, which means faster iteration cycles, quicker time-to-market for AI products, and reduced overall compute costs. The 75% reduction in memory usage through FP8 precision means you can train larger models on fewer GPUs, and the superior performance-per-watt compared to previous generations reduces energy costs for long-running training jobs. At Cyfuture Cloud, we offer flexible pricing models including on-demand and reserved instances that allow you to optimize costs based on your specific usage patterns, ensuring you get maximum value from H100’s performance advantages.
Does Cyfuture Cloud provide support for optimizing AI workloads on H100 infrastructure?
Yes, Cyfuture Cloud provides comprehensive support beyond just hardware access. Our team of AI infrastructure experts can help you optimize your workloads for H100 architecture, including guidance on leveraging the Transformer Engine for maximum performance, best practices for distributed training across multiple H100 GPUs, memory optimization strategies using MIG technology, and framework-specific optimizations for PyTorch, TensorFlow, and other popular AI platforms. We also offer architectural consulting to help you design your AI infrastructure for scalability and efficiency, 24/7 technical support to address any infrastructure issues, and regular performance monitoring and optimization recommendations. Our goal is to ensure you extract maximum value from H100’s capabilities while focusing your team’s efforts on AI innovation rather than infrastructure management.
Recent Post




















Stay Ahead of the Curve.
Join the Cloud Movement, today!
Send this to a friend