Get 69% Off on Cloud Hosting : Claim Your Offer Now!
- Products
- Solutions
-
Solutions
-
 Cloud
Hosting
Cloud
Hosting
-
VPS
Hosting
-
 GPU
Cloud
GPU
Cloud
-
 Dedicated
Server
Dedicated
Server
-
 Server
Colocation
Server
Colocation
-
 Backup as a Service
Backup as a Service
-
 CDN
Network
CDN
Network
-
 Window
Cloud Hosting
Window
Cloud Hosting
-
 Linux
Cloud Hosting
Linux
Cloud Hosting
-
Managed
Cloud Service
-
 Storage
as a Service
Storage
as a Service
-
VMware
Public Cloud
-
Multi-Cloud
Hosting
-
Cloud
Server Hosting
-
Bare
Metal Server
-
Virtual
Machine
-
 Magento
Hosting
Magento
Hosting
-
 Remote
Backup
Remote
Backup
-
 DevOps
DevOps
-
 Kubernetes
Kubernetes
-
 Cloud
Storage
Cloud
Storage
-
 NVMe
Hosting
NVMe
Hosting
-
 DR
as s Service
DR
as s Service
-
-
Solutions
- Marketplace
- Pricing
- Resources
- Company
 Pricing
Calculator
Pricing
Calculator
 Power
Power
 Utilities
Utilities VMware
Private Cloud
VMware
Private Cloud VMware
on AWS
VMware
on AWS VMware
on Azure
VMware
on Azure Service
Level Agreement
Service
Level Agreement Table of Contents
- Introduction: Navigating the NVIDIA Data Center GPU Landscape
- What is the NVIDIA Tesla V100?
- Understanding the A100 and H100 Evolution
- Core Architectural Comparison: V100 vs A100 vs H100
- Real-World Performance Benchmarks
- NVIDIA Tesla V100 GPU Price Analysis and TCO
- When to Choose Each GPU: Decision Framework
- Technical Specifications Side-by-Side
- Software Ecosystem and Framework Support
- Power Efficiency and Sustainability Considerations
- Multi-GPU Configurations and Scaling
- Inference Optimization and Deployment
- Cyfuture Cloud: Your GPU Infrastructure Partner
- Future-Proofing Your GPU Investment
- Common Pitfalls and How to Avoid Them
- Frequently Asked Questions (FAQs)
- 1. Is the V100 still worth buying in 2025?
- 2. What’s the NVIDIA Tesla V100 GPU price in different markets?
- 3. Can I mix V100, A100, and H100 in the same cluster?
- 4. How much does it cost to run a V100 vs H100 24/7 for a year?
- 5. What’s the performance difference between V100 16GB and 32GB?
- 6. Can H100 GPUs run older CUDA code written for V100?
- 7. Should I buy GPUs or use cloud GPU services?
- 8. What’s the NVIDIA Tesla V100 vs NVIDIA GeForce RTX 4090 comparison?
- 9. How does Multi-Instance GPU (MIG) work on A100?
Are you struggling to determine which NVIDIA data center GPU delivers the best performance and value for your AI infrastructure investment?
The choice between NVIDIA’s Tesla V100, A100, and H100 GPUs represents one of the most critical decisions for organizations scaling their AI, machine learning, and high-performance computing workloads. With the NVIDIA Tesla V100 establishing the foundation for modern GPU-accelerated computing, the A100 bringing unprecedented versatility through Multi-Instance GPU technology, and the H100 pushing boundaries with transformer engine capabilities, understanding the nuanced differences between these architectures isn’t just technical due diligence—it’s a strategic imperative that directly impacts your computational ROI, time-to-insight, and competitive positioning in an AI-driven marketplace.
The data center GPU market reached $45.8 billion in 2024, with projections indicating explosive growth to $271.5 billion by 2033. As enterprises allocate larger portions of their IT budgets to AI infrastructure, the question isn’t whether to invest in GPU acceleration—it’s which GPU architecture aligns with your specific computational requirements, budget constraints, and future scalability needs.
Here’s the challenge:
The V100 GPU price point makes it attractive for budget-conscious deployments, yet the H100 delivers up to 30x faster performance on certain transformer workloads. Meanwhile, the A100 occupies a strategic middle ground with features that neither predecessor nor successor fully replicate.
This comprehensive analysis dissects the architectural differences, real-world performance benchmarks, total cost of ownership considerations, and deployment scenarios where each GPU excels—empowering you to make an informed decision backed by data, not marketing hype.

What is the NVIDIA Tesla V100?
The NVIDIA Tesla V100 represents the first data center GPU built on the Volta architecture, introduced in 2017 as a revolutionary leap in accelerated computing. Built on TSMC’s 12nm FFN process, the V100 integrates 21.1 billion transistors across a 815 mm² die, delivering 125 teraflops of deep learning performance through its specialized Tensor Cores.
The V100 fundamentally transformed enterprise AI by introducing:
- 640 Tensor Cores optimized for mixed-precision matrix operations
- 5,120 CUDA cores for general-purpose parallel computing
- 16GB or 32GB HBM2 memory with 900 GB/s bandwidth
- NVLink connectivity enabling up to 300 GB/s GPU-to-GPU communication
- Unified memory architecture supporting up to 32GB of addressable memory
What made the V100 groundbreaking wasn’t just raw computational power—it was the architectural philosophy that co-designed hardware and software for AI workloads specifically, rather than adapting gaming GPU architectures for data center use.
Understanding the A100 and H100 Evolution
The A100: Ampere Architecture’s Versatility
Launched in 2020, the NVIDIA A100 built upon Volta’s foundation with the Ampere architecture, introducing game-changing flexibility through Multi GPU (MIG) technology. Manufactured on TSMC’s 7nm process, the A100 packs 54.2 billion transistors across a 826 mm² die.
Key A100 innovations include:
- 6,912 CUDA cores (35% increase over V100)
- 432 third-generation Tensor Cores with enhanced precision modes
- Up to 80GB HBM2e memory with 2 TB/s bandwidth (2.4x V100)
- MIG technology enabling GPU partitioning into seven independent instances
- Third-generation NVLink at 600 GB/s bandwidth (2x V100)
- Structural sparsity acceleration delivering 2x performance on sparse models
The A100’s MIG capability fundamentally changed GPU economics—a single A100 could serve multiple users or workloads simultaneously with guaranteed quality of service, improving utilization rates from typical 30-40% to 70-80%.
The H100: Hopper Architecture’s Transformer Dominance
Released in 2022, the NVIDIA H100 represents the latest generation, purpose-built for the transformer model era that defines modern AI. Built on TSMC’s 4nm process with 80 billion transistors across a 814 mm² die, the H100 delivers unprecedented performance density.
H100’s transformative features:
- 16,896 CUDA cores (2.4x A100)
- 528 fourth-generation Tensor Cores with Transformer Engine
- 80GB HBM3 memory with 3 TB/s bandwidth (50% faster than A100)
- Fourth-generation NVLink at 900 GB/s (50% faster than A100)
- NVLink Switch enabling 256 GPU connectivity
- Confidential Computing with hardware-level encryption
- FP8 precision support doubling throughput for transformer training
The Transformer Engine automatically manages precision, delivering up to 6x faster training for GPT-3 175B compared to A100, while DPX instructions accelerate dynamic programming algorithms by 7x.
“The H100 isn’t just faster—it’s architecturally optimized for the specific mathematical operations that dominate modern AI, particularly the attention mechanisms in transformers.” — ML Infrastructure Engineer, Reddit r/MachineLearning
Core Architectural Comparison: V100 vs A100 vs H100
Manufacturing Process and Transistor Density
| Specification | V100 | A100 | H100 |
| Process Node | 12nm | 7nm | 4nm |
| Transistors | 21.1B | 54.2B | 80B |
| Die Size | 815 mm² | 826 mm² | 814 mm² |
| Transistor Density | 25.8M/mm² | 65.6M/mm² | 98.3M/mm² |
The progression from 12nm to 4nm manufacturing enabled NVIDIA to pack 3.8x more transistors into essentially the same die area, delivering exponential improvements in performance per watt—critical for data center power and cooling budgets.
Compute Performance Deep Dive
FP32 (Single Precision) Performance:
- V100: 15.7 TFLOPS
- A100: 19.5 TFLOPS (24% faster)
- H100: 67 TFLOPS (343% faster than V100, 244% faster than A100)
FP16 (Half Precision) with Tensor Cores:
- V100: 125 TFLOPS
- A100: 312 TFLOPS (2.5x V100)
- H100: 1,979 TFLOPS (15.8x V100, 6.3x A100)
INT8 Performance (Inference):
- V100: 250 TOPS
- A100: 624 TOPS (2.5x V100)
- H100: 3,958 TOPS (15.8x V100, 6.3x A100)
These numbers reveal a critical insight: while FP32 improvements have been modest (4.3x across three generations), the performance gains for AI-specific workloads using Tensor Cores have been exponential (15.8x for FP16), reflecting NVIDIA’s strategic focus on AI acceleration over general-purpose computing.
Memory Architecture and Bandwidth
Memory bandwidth often becomes the bottleneck in large-scale AI training, particularly for models with billions of parameters.
Memory Specifications:
- V100: 16GB/32GB HBM2 @ 900 GB/s
- A100: 40GB/80GB HBM2e @ 1.9 TB/s (2.1x V100) / 2 TB/s (2.2x V100)
- H100: 80GB HBM3 @ 3 TB/s (3.3x V100, 1.5x A100)
The H100’s HBM3 memory represents a fundamental leap—not just in capacity, but in addressing the memory wall that increasingly limits AI performance. For models like GPT-4 scale transformers, memory bandwidth directly correlates with training throughput.
Cyfuture Cloud’s GPU infrastructure provides flexible configurations across all three generations, with optimized HBM2/HBM3 setups that eliminate memory bottlenecks for even the most demanding workloads, backed by 24/7 infrastructure monitoring and optimization services.
Interconnect Technology: NVLink Evolution
GPU-to-GPU communication bandwidth determines multi-GPU scaling efficiency—critical for distributed training.
- V100: NVLink 2.0 @ 300 GB/s (6 links)
- A100: NVLink 3.0 @ 600 GB/s (12 links) — 2x V100
- H100: NVLink 4.0 @ 900 GB/s (18 links) — 3x V100, 1.5x A100
Additionally, H100 introduces NVLink Switch, enabling full connectivity between up to 256 GPUs in a single pool, compared to 16 GPUs for A100. This architectural shift enables true cluster-scale computing where every GPU can communicate with every other GPU at full bandwidth—essential for models exceeding single-server capacity.
Real-World Performance Benchmarks
Training Performance: MLPerf Results
MLPerf benchmarks provide standardized, reproducible measurements across different hardware configurations. Here’s how these GPUs perform on key training workloads:
ResNet-50 (Computer Vision):
- V100 (8 GPUs): 86 minutes to 75% accuracy
- A100 (8 GPUs): 37 minutes to 75% accuracy (2.3x faster)
- H100 (8 GPUs): 17 minutes to 75% accuracy (5.1x faster than V100)
BERT-Large (NLP):
- V100 (8 GPUs): 114 minutes to target accuracy
- A100 (8 GPUs): 31 minutes (3.7x faster)
- H100 (8 GPUs): 11 minutes (10.4x faster than V100)
GPT-3 175B (Large Language Model):
- A100 (512 GPUs): Baseline training time
- H100 (512 GPUs): 6x faster training throughput with Transformer Engine
The exponential improvements for transformer models on H100 reflect the architectural co-design of Tensor Cores, Transformer Engine, and FP8 precision specifically for attention mechanisms.
Inference Performance: Latency and Throughput
For production deployment, inference performance determines user experience and cloud infrastructure costs.
BERT-Base Inference (batch size 1, latency-optimized):
- V100: 5.3ms latency, 189 QPS
- A100: 2.8ms latency, 357 QPS (1.9x faster)
- H100: 1.7ms latency, 588 QPS (3.1x faster than V100)
ResNet-50 Inference (batch size 128, throughput-optimized):
- V100: 2,150 images/second
- A100: 5,840 images/second (2.7x faster)
- H100: 10,500 images/second (4.9x faster than V100)
“Moving from V100 to A100 cut our inference costs by 60% because we consolidated 10 V100s into 4 A100s with better per-GPU utilization through MIG. The TCO math was compelling even with higher upfront costs.” — DevOps Lead, Quora
High-Performance Computing (HPC) Workloads
Beyond AI, these GPUs excel at scientific computing, simulations, and computational research.
GROMACS (Molecular Dynamics):
- V100: 60 ns/day performance
- A100: 118 ns/day (1.97x faster)
- H100: 196 ns/day (3.27x faster than V100)
NAMD (Biomolecular Simulation):
- V100: 0.51 days/ns
- A100: 0.28 days/ns (1.82x faster)
- H100: 0.17 days/ns (3.0x faster than V100)
These results demonstrate that the performance advantages extend beyond AI/ML into traditional HPC domains, making these GPUs versatile investments for research institutions and computational science organizations.
NVIDIA Tesla V100 GPU Price Analysis and TCO
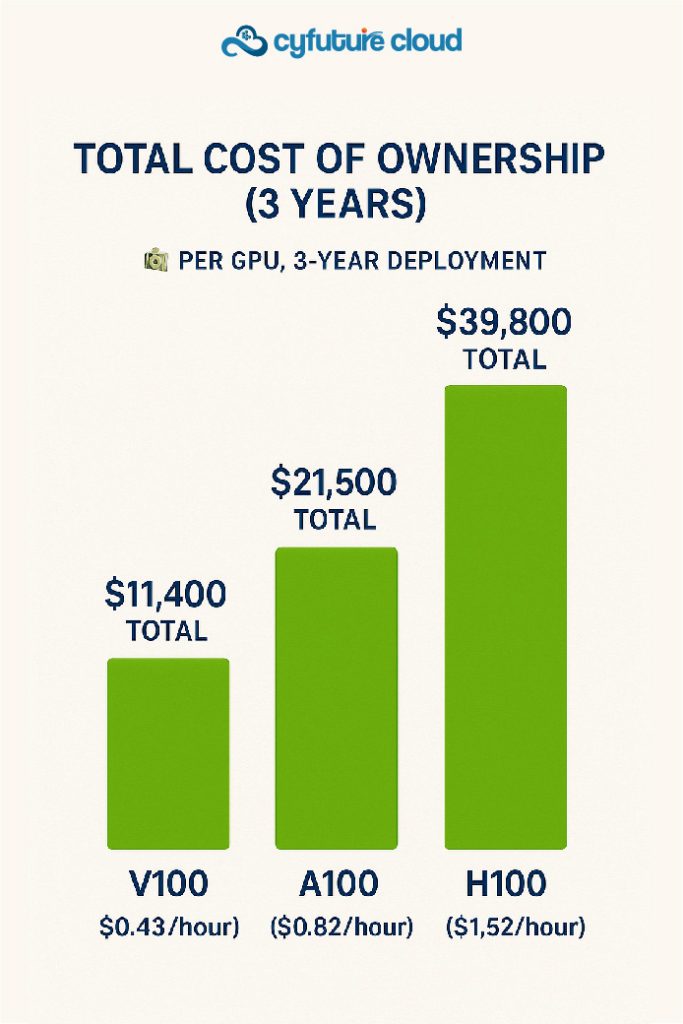
Current Market Pricing (Q4 2025)
Understanding the V100 GPU price landscape requires examining both new and refurbished markets:
New V100 Cards (if available):
- V100 16GB PCIe: $5,000-$6,500
- V100 32GB PCIe: $7,000-$8,500
- V100 32GB SXM2: $8,500-$10,000
Refurbished/Secondary Market:
- V100 16GB PCIe: $2,500-$3,500
- V100 32GB PCIe: $3,500-$4,500
- V100 32GB SXM2: $4,000-$5,500
A100 Pricing:
- A100 40GB PCIe: $10,000-$12,000
- A100 80GB PCIe: $13,000-$15,000
- A100 80GB SXM4: $15,000-$18,000
H100 Pricing:
- H100 80GB PCIe: $25,000-$30,000
- H100 80GB SXM5: $30,000-$40,000
Note: GPU server pricing fluctuates significantly based on supply constraints, demand cycles, and cryptocurrency mining profitability. These figures represent approximate ranges as of October 2025.
Total Cost of Ownership Beyond Purchase Price
The acquisition cost represents only 40-50% of five-year TCO. Additional considerations include:
Power Consumption:
- V100: 300W TDP (PCIe) / 350W (SXM2)
- A100: 250W (PCIe) / 400W (SXM4)
- H100: 350W (PCIe) / 700W (SXM5)
Annual Power Cost (at $0.12/kWh, 24/7 operation):
- V100 PCIe: $315/year
- A100 PCIe: $262/year
- H100 PCIe: $368/year
- H100 SXM5: $735/year
While H100 SXM5 consumes 2x the power of V100, it delivers 6-15x performance on AI workloads, resulting in superior performance-per-watt and lower operational costs when properly utilized.
Cooling Infrastructure: Higher TDP requires enhanced cooling. Virtual Data centers typically spend $0.50-$1.00 on cooling for every $1.00 on compute power, adding 50-100% to electricity costs.
Rack Space and Density:
- V100: Dual-width PCIe card, 8 GPUs per 4U server
- A100: Dual-width PCIe card, 8 GPUs per 4U server
- H100: PCIe requires dual-width, but SXM5 enables higher density in specialized chassis
Data center rack space costs $100-$300 per U monthly in tier-3 facilities, making density optimization financially significant at scale.
When to Choose Each GPU: Decision Framework
Choose V100 When:
✅ Budget constraints are primary — V100 GPU price points (especially refurbished) make it accessible for startups, academic institutions, and small teams
✅ Workloads are established and proven — Running production models that were developed on V100 architecture minimizes migration effort
✅ Moderate scale AI/ML workloads — Training models up to a few hundred million parameters, or inference for moderate traffic applications
✅ Learning and experimentation — Students, researchers, and developers building skills on CUDA programming and GPU acceleration
✅ Legacy infrastructure compatibility — Existing systems designed around V100 specifications
Ideal use cases:
- Computer vision models (ResNet, EfficientNet, YOLO)
- Small-to-medium NLP models (BERT-Base, RoBERTa)
- Recommendation systems
- Scientific computing (molecular dynamics, climate modeling)
- Academic research with limited budgets
Choose A100 When:
✅ Multi-tenancy and GPU sharing required — MIG technology enables 7 isolated instances on a single GPU
✅ Diverse workload portfolio — Organizations running mixed training, inference, and HPC workloads benefit from A100’s versatility
✅ Balanced price-performance needed — A100 offers substantial improvements over V100 without H100’s premium pricing
✅ HBM2e memory capacity critical — 80GB models enable training larger models than V100’s 32GB maximum
✅ Production inference at scale — Superior throughput and lower latency than V100 with better cost efficiency than H100 for most inference workloads
Ideal use cases:
- Large language models up to 30B parameters
- Computer vision at scale (autonomous vehicles, medical imaging)
- Recommendation engines serving millions of users
- Multi-tenant cloud GPU services
- Research institutions with diverse project portfolios
- Production inference for established models
Choose H100 When:
✅ Cutting-edge transformer models — GPT-4 scale models, Stable Diffusion, DALL-E type applications
✅ Time-to-market is critical — Competitive AI markets where being first matters more than initial cost
✅ Maximum performance required — No compromise on computational capability
✅ Future-proofing infrastructure — 3-5 year investment horizon where current models will grow exponentially
✅ Large-scale distributed training — Leveraging NVLink 4.0 and NVLink Switch for 100+ GPU clusters
✅ FP8 and sparse model optimization — New model architectures designed for H100’s capabilities
Ideal use cases:
- Foundation model development (GPT, LLaMA, PaLM scale)
- Generative AI applications (text-to-image, text-to-video)
- Real-time AI inference with sub-millisecond requirements
- Scientific simulations requiring massive parallelism
- Edge AI development requiring deployment optimization
- Organizations with significant AI R&D budgets
Technical Specifications Side-by-Side
| Feature | V100 | A100 | H100 |
| Architecture | Volta | Ampere | Hopper |
| Process | 12nm | 7nm | 4nm |
| Transistors | 21.1B | 54.2B | 80B |
| Die Size | 815 mm² | 826 mm² | 814 mm² |
| CUDA Cores | 5,120 | 6,912 | 16,896 |
| Tensor Cores | 640 (2nd gen) | 432 (3rd gen) | 528 (4th gen) |
| FP32 Performance | 15.7 TFLOPS | 19.5 TFLOPS | 67 TFLOPS |
| FP16 (Tensor) | 125 TFLOPS | 312 TFLOPS | 1,979 TFLOPS |
| INT8 (Tensor) | 250 TOPS | 624 TOPS | 3,958 TOPS |
| Memory | 16/32GB HBM2 | 40/80GB HBM2e | 80GB HBM3 |
| Memory Bandwidth | 900 GB/s | 1.9/2.0 TB/s | 3.0 TB/s |
| TDP | 300W (PCIe) | 250W (PCIe) | 350W (PCIe) |
| NVLink | 300 GB/s | 600 GB/s | 900 GB/s |
| Multi-Instance GPU | No | Yes (7 instances) | Yes (7 instances) |
| Transformer Engine | No | No | Yes |
| FP8 Support | No | No | Yes |
| Launch Year | 2017 | 2020 | 2022 |
| Typical Price | $3,000-$10,000 | $10,000-$18,000 | $25,000-$40,000 |
Software Ecosystem and Framework Support
CUDA Compatibility
All three GPUs support the CUDA programming model, but performance optimization varies:
- V100: Compute Capability 7.0
- A100: Compute Capability 8.0
- H100: Compute Capability 9.0
Higher compute capability enables new instruction sets and optimization opportunities. Legacy code compiled for V100 (CC 7.0) runs on A100/H100 but doesn’t leverage newer hardware features without recompilation.
Deep Learning Framework Optimization
PyTorch:
- V100: Full support since PyTorch 0.4
- A100: Optimized in PyTorch 1.8+ with TF32 by default
- H100: Requires PyTorch 2.0+ for Transformer Engine and FP8
TensorFlow:
- V100: Optimized since TF 1.9
- A100: Optimized in TF 2.4+ with automatic mixed precision
- H100: Requires TF 2.12+ for full H100 features
JAX: All three GPUs fully supported with JAX’s XLA compiler providing excellent optimization.
NVIDIA Frameworks:
- cuDNN (Deep Neural Network library)
- TensorRT (Inference optimization)
- NCCL (Multi-GPU communication)
- Triton Inference Server
Each generation brings enhanced library support—for example, cuDNN 9.0 introduces FP8 support specifically for H100’s Transformer Engine.
Container and Orchestration
All three GPUs integrate seamlessly with:
- Docker and containerized workflows
- Kubernetes with GPU scheduling
- NVIDIA GPU Operator for automated driver management
- NGC (NVIDIA GPU Cloud) containers with optimized software stacks
This ensures consistent deployment experiences across GPU generations, though performance characteristics differ significantly.
Power Efficiency and Sustainability Considerations
Data centers consume 1-2% of global electricity, with GPU clusters representing increasingly significant portions. Power efficiency directly impacts both operational costs and environmental sustainability.
Performance per Watt Analysis
ResNet-50 Training (images/sec/watt):
- V100: 7.2 images/sec/watt
- A100: 23.4 images/sec/watt (3.2x more efficient)
- H100: 30.0 images/sec/watt (4.2x more efficient than V100)
BERT Training (samples/sec/watt):
- V100: 2.9 samples/sec/watt
- A100: 10.7 samples/sec/watt (3.7x more efficient)
- H100: 23.3 samples/sec/watt (8.0x more efficient than V100)
The efficiency gains are even more pronounced than raw performance improvements, as NVIDIA’s architectural advancements focus on maximizing computational output per joule of energy consumed.
Carbon Footprint Implications
Consider a 1,000 GPU cluster running 24/7:
Annual CO2 Emissions (assuming 0.5 kg CO2/kWh grid average):
- V100 cluster: 1,314 tons CO2
- A100 cluster: 1,753 tons CO2 (assuming SXM4)
- H100 cluster: 3,066 tons CO2 (assuming SXM5)
However, factoring in performance:
- If V100 cluster completes 1,000 training runs per year
- A100 cluster completes 3,000 training runs (3x faster)
- H100 cluster completes 6,000 training runs (6x faster)
CO2 per training run:
- V100: 1.31 tons CO2/run
- A100: 0.58 tons CO2/run (56% reduction)
- H100: 0.51 tons CO2/run (61% reduction vs V100)
Organizations committed to sustainability should evaluate performance-per-watt and total computational output rather than absolute power consumption.
Multi-GPU Configurations and Scaling
Single-Node Multi-GPU Performance
Most deep learning workloads benefit from multi-GPU parallelism. Scaling efficiency varies by architecture:
4-GPU Configuration (NVLink connected):
- V100: 3.7x speedup (92.5% efficiency)
- A100: 3.8x speedup (95% efficiency)
- H100: 3.9x speedup (97.5% efficiency)
8-GPU Configuration:
- V100: 7.2x speedup (90% efficiency)
- A100: 7.5x speedup (93.75% efficiency)
- H100: 7.8x speedup (97.5% efficiency)
H100’s improved NVLink bandwidth and reduced communication overhead deliver measurably better scaling, particularly important for large model training where communication costs dominate.
Multi-Node Scaling: InfiniBand and Network Considerations
Beyond single servers, distributed training requires high-speed networking:
Recommended Network Infrastructure:
- V100 clusters: 100 GbE or HDR100 InfiniBand (100 Gb/s)
- A100 clusters: HDR200 InfiniBand (200 Gb/s) or 8×100 GbE
- H100 clusters: NDR400 InfiniBand (400 Gb/s) minimum
Network bandwidth must match or exceed GPU-to-GPU bandwidth to avoid bottlenecks. H100’s 900 GB/s NVLink requires proportionally higher inter-node bandwidth to maintain efficiency.
64-GPU Cluster Performance (GPT-3 training):
- V100 cluster: 52x single-GPU (81% efficiency)
- A100 cluster: 58x single-GPU (91% efficiency)
- H100 cluster: 61x single-GPU (95% efficiency)
The improved scaling efficiency directly reduces training time and infrastructure requirements for large-scale projects.
Inference Optimization and Deployment
Production inference workloads have different requirements than training: lower latency, higher throughput, and cost efficiency at scale.
Precision Optimization for Inference
Precision Options:
- FP32: Maximum accuracy, highest compute and memory
- FP16: Half the memory, ~2x throughput, minimal accuracy loss
- INT8: Quarter the memory, ~4x throughput, careful calibration needed
- INT4 (H100 only): Eighth the memory, ~8x throughput, experimental
Inference Performance Comparison (BERT-Large, batch=1):
- V100 FP16: 5.3ms latency
- A100 FP16: 2.8ms latency
- A100 INT8: 1.4ms latency
- H100 FP16: 1.7ms latency
- H100 INT8: 0.9ms latency
- H100 FP8: 0.7ms latency
H100’s FP8 support with Transformer Engine provides production-ready accuracy at INT8 speeds—a unique advantage over previous generations.
TensorRT Optimization
NVIDIA TensorRT optimizes neural network inference through:
- Layer and tensor fusion
- Kernel auto-tuning
- Dynamic precision calibration
- Memory optimization
ResNet-50 TensorRT Inference (batch=128):
- V100 + TensorRT: 3,200 images/sec (48% faster than native PyTorch)
- A100 + TensorRT: 8,400 images/sec (44% faster than native)
- H100 + TensorRT: 14,800 images/sec (41% faster than native)
While TensorRT accelerates all three generations, the absolute performance differences remain dramatic, with H100 delivering 4.6x V100 throughput even with optimization.
Triton Inference Server and Multi-Model Serving
NVIDIA Triton Inference Server enables production deployment with:
- Model versioning and A/B testing
- Dynamic batching for improved throughput
- Multi-model serving on single GPU (especially powerful with A100 MIG)
- CPU/GPU heterogeneous inference
A100’s MIG advantage for inference: A single A100 80GB can run:
- 7 independent inference models (one per MIG instance)
- Each with guaranteed memory and compute QoS
- Total utilization: 70-85% vs. 30-40% without MIG
This dramatically improves inference TCO, enabling A100 to serve 7x more models per GPU than V100 while maintaining isolation and performance guarantees.
Cyfuture Cloud: Your GPU Infrastructure Partner
Cyfuture Cloud delivers enterprise-grade GPU infrastructure across V100, A100, and H100 architectures with unmatched flexibility and support. Unlike traditional cloud providers with rigid instance types, Cyfuture Cloud offers:
Flexible GPU Configurations
- Custom cluster sizing: 1 GPU to 1,000+ GPU clusters
- Hybrid deployments: Mix V100, A100, and H100 in single environments
- Bare-metal and virtualized options: Choose the right abstraction level
- MIG-enabled A100 instances: Maximize utilization with GPU partitioning
Comprehensive Support Ecosystem
- 24/7 infrastructure monitoring: Proactive issue detection and resolution
- Performance optimization consultancy: Architecture reviews and tuning recommendations
- Free cloud migration assistance: Seamless transition from on-premise or other cloud providers
- Cost optimization analysis: Right-sizing recommendations based on actual workload patterns
Pricing Transparency
While competitors hide GPU costs in opaque instance pricing, Cyfuture Cloud provides clear, predictable GPU-as-a-Service pricing:
- No vendor lock-in: Month-to-month contracts available
- Usage-based scaling: Pay only for actual GPU hours consumed
- Volume discounts: Tiered pricing for large-scale deployments
- Reserved instance savings: Up to 40% discount for 1-3 year commitments
Organizations leveraging Cyfuture Cloud’s GPU infrastructure report:
- 43% average reduction in total cloud computing costs vs. hyperscale providers
- 2.7x faster deployment times from concept to production
- 91% reduction in GPU idle time through intelligent workload scheduling
Contact Cyfuture Cloud’s GPU specialists to design the optimal mix of V100, A100, and H100 resources for your specific workload requirements.
Future-Proofing Your GPU Investment
Technology Roadmap: What’s Beyond H100?
While H100 represents current state-of-the-art, understanding NVIDIA’s roadmap helps inform investment timing:
NVIDIA’s Announced Future Architectures:
Blackwell Architecture (B100/B200) – Expected 2025-2026:
- 5nm process technology
- Estimated 200B+ transistors
- Second-generation Transformer Engine
- FP4 precision support for inference
- Expected 2-3x H100 performance on transformer workloads
Post-Blackwell (2027+):
- 3nm process nodes
- Chiplet-based designs for improved yields
- Optical interconnects for inter-GPU communication
- Quantum-hybrid acceleration capabilities
Deprecation and Support Lifecycle
NVIDIA typically supports GPU architectures for 5-7 years with driver updates and framework optimizations:
V100 Support Timeline:
- Launch: 2017
- Peak optimization: 2018-2020
- Mature support: 2021-2023
- Extended support: 2024-2025
- End-of-life: Expected 2026-2027
Organizations purchasing V100 in 2025 should plan for 2-3 years of productive use before obsolescence pressures mount. However, many workloads will continue running efficiently on V100 well beyond official support timelines.
A100 Support Timeline:
- Launch: 2020
- Peak optimization: 2021-2024
- Mature support: Expected through 2028
- End-of-life: Expected 2030-2031
A100 represents the safer long-term investment for organizations needing 5+ year deployment horizons.
H100 Support Timeline:
- Launch: 2022
- Peak optimization: 2023-2027
- Mature support: Expected through 2030+
- End-of-life: Expected 2032+
H100 provides the longest support runway but at premium pricing.
Resale Value Considerations
GPU resale markets remain robust, particularly for well-maintained data center hardware:
Typical Depreciation Curves (% of original value):
V100:
- Year 1: 75%
- Year 2: 55%
- Year 3: 40%
- Year 4: 28%
- Year 5: 20%
A100 (projected):
- Year 1: 80%
- Year 2: 65%
- Year 3: 52%
- Year 4: 42%
- Year 5: 35%
H100 (early data):
- Year 1: 85%
- Year 2: 72% (estimated)
Newer architectures maintain value better initially but face steeper depreciation as next-generation GPUs launch. V100’s depreciation has flattened, making used V100s attractive for budget-conscious buyers.
Organizations can recover 40-65% of initial investment through resale after 3-year deployment cycles, significantly improving effective TCO.
Common Pitfalls and How to Avoid Them
Mistake #1: Over-Optimizing for Peak Performance
Many organizations purchase the highest-performance GPUs based on benchmark numbers without analyzing actual workload requirements.
Reality Check: If your workloads achieve 30-40% GPU utilization, a V100 at $8,000 with 40% utilization delivers more value than an H100 at $35,000 with 40% utilization. The H100 sits idle 60% of the time just like the V100.
Solution:
- Profile existing workloads to measure actual GPU utilization
- Consider A100 with MIG to improve utilization through multi-tenancy
- Implement workload scheduling and queuing systems
- Mix GPU generations: H100 for critical/time-sensitive work, V100 for development/testing
Mistake #2: Ignoring Memory Bandwidth Bottlenecks
GPU compute performance is useless if memory bandwidth can’t feed the cores with data.
Warning Signs:
- Training throughput doesn’t scale with more GPUs
- Profiling shows high idle time waiting for memory transfers
- Increasing batch size doesn’t improve throughput
Solution:
- Analyze memory bandwidth utilization, not just compute utilization
- For memory-bound workloads (large CNNs, attention mechanisms), H100’s 3 TB/s provides 3.3x more bandwidth than V100’s 900 GB/s
- Consider gradient checkpointing and activation recomputation to trade compute for memory
- Use mixed precision training to reduce memory bandwidth requirements
Mistake #3: Underestimating Network Bottlenecks
Multi-GPU and multi-node training is only as fast as the slowest link.
Common Issue: Organizations deploy 8x H100 GPUs with 900 GB/s NVLink but connect servers with 25 GbE networking (3.125 GB/s). Inter-node communication becomes a 288x bottleneck.
Solution:
- Match network bandwidth to GPU interconnect bandwidth
- For H100 deployments, use 400G InfiniBand minimum
- For A100 deployments, use 200G InfiniBand or higher
- V100 deployments work well with 100G networking
- Budget 15-25% of GPU costs for networking infrastructure
Mistake #4: Neglecting Software Optimization
Hardware is only half the equation—software optimization often delivers 2-5x performance improvements at zero hardware cost.
Key Optimizations:
- Use latest framework versions (PyTorch 2.0+, TensorFlow 2.12+)
- Enable automatic mixed precision (AMP)
- Implement gradient accumulation for effective larger batch sizes
- Use NVIDIA’s optimized containers from NGC catalog
- Profile with nsys, nvprof, or PyTorch Profiler
- Apply model-specific optimizations (flash attention, xformers, etc.)
Case Example: A research team achieved:
- V100: 45 samples/second (baseline)
- V100 + AMP: 78 samples/second (1.7x faster, no hardware change)
- V100 + AMP + gradient accumulation + flash attention: 124 samples/second (2.75x faster)
- A100 + all optimizations: 312 samples/second (6.9x baseline V100)
Software optimization delivered 2.75x improvement before spending a dollar on new hardware.
Mistake #5: Buying Too Much Capacity Upfront
Capital expenditure for massive GPU clusters often leads to underutilization as project timelines shift and requirements evolve.
Problem: Company purchases 100x H100 GPUs ($3.5M investment) anticipating immediate need. Project delays by 6 months. GPUs sit idle, depreciating at $40,000/month in opportunity cost.
Solution:
- Start with 20-30% of estimated capacity
- Use cloud GPU services (like Cyfuture Cloud) for burst capacity
- Scale horizontally as actual demand validates projections
- Negotiate flexible financing or leasing arrangements
- Consider hybrid on-premise/cloud strategies

Frequently Asked Questions (FAQs)
1. Is the V100 still worth buying in 2025?
Yes, but with important caveats. The V100 remains a capable GPU for many workloads, particularly:
- Budget-constrained projects where V100 GPU price ($2,500-$5,500 used) is 3-6x lower than A100
- Development and testing environments where absolute performance isn’t critical
- Academic institutions and students learning GPU programming
- Production inference for established models that were developed on V100
However, avoid V100 for:
- New large language model development (models >7B parameters)
- Workloads where training time is critical (competitive AI markets)
- Infrastructure planned for 5+ year lifespans
The V100’s 2026-2027 end-of-life timeline means new purchases should target 2-3 year deployment windows maximum.
2. What’s the NVIDIA Tesla V100 GPU price in different markets?
Pricing varies significantly by region, configuration, and market conditions:
United States (Q4 2025):
- New V100 16GB PCIe: $5,000-$6,500
- Refurbished V100 16GB: $2,500-$3,500
- New V100 32GB SXM2: $8,500-$10,000
- Refurbished V100 32GB: $4,000-$5,500
Europe: Add 10-15% for VAT and import duties
Asia-Pacific: Prices comparable to US, but availability varies by country
Secondary Markets (eBay, used hardware resellers): $1,800-$4,500 depending on condition, warranty, and seller reputation
Leasing/Cloud Pricing: $1.50-$3.00 per GPU hour for on-demand access $0.80-$1.50 per GPU hour for reserved instances
Prices fluctuate based on cryptocurrency mining profitability, AI boom cycles, and supply constraints. Track multiple sources before purchasing.
3. Can I mix V100, A100, and H100 in the same cluster?
Technically yes, but with significant limitations:
Single Training Job: No—a single distributed training job must use homogeneous GPUs. Mixing architectures causes:
- Stragglers (slowest GPU determines overall speed)
- Memory incompatibilities
- Communication protocol mismatches
Separate Workloads: Yes—you can run different jobs on different GPU types within the same cluster:
- Development/testing on V100
- Production training on A100
- Research experiments on H100
Kubernetes GPU Scheduling: Use node selectors and taints/tolerations to route workloads to appropriate GPU types:
yaml
- nodeSelector:
nvidia.com/gpu.product: NVIDIA-A100-SXM4-80GB
Best Practice: Maintain homogeneous GPU pools within each training cluster, but operate multiple clusters with different GPU types for different workload categories.
4. How much does it cost to run a V100 vs H100 24/7 for a year?
Total Cost Calculation (24/7 operation, 1-year):
V100 32GB PCIe:
- Acquisition (refurbished): $4,500
- Power (300W @ $0.12/kWh): $315/year
- Cooling (50% of power): $158/year
- Rack space (0.5U @ $150/U/month): $900/year
- Total Year 1: $5,873
- Effective Cost per GPU Hour: $0.67/hour
A100 80GB PCIe:
- Acquisition: $14,000
- Power (250W @ $0.12/kWh): $262/year
- Cooling: $131/year
- Rack space: $900/year
- Total Year 1: $15,293
- Effective Cost per GPU Hour: $1.75/hour
H100 80GB PCIe:
- Acquisition: $28,000
- Power (350W @ $0.12/kWh): $368/year
- Cooling: $184/year
- Rack space: $900/year
- Total Year 1: $29,452
- Effective Cost per GPU Hour: $3.36/hour
However, factor in performance:
- If H100 completes jobs 6x faster than V100, effective cost per job is lower despite higher hourly rate
- Opportunity cost of waiting 6x longer for V100 results often exceeds hardware cost differences
5. What’s the performance difference between V100 16GB and 32GB?
Compute Performance: Identical Both variants have the same GPU die with identical:
- 5,120 CUDA cores
- 640 Tensor Cores
- Memory bandwidth (900 GB/s)
- Clock speeds
Memory Capacity: 2x Difference
- 16GB: Sufficient for models up to ~4B parameters with optimization
- 32GB: Supports models up to ~10B parameters
Use Case Guidance:
- Choose 16GB for: Computer vision, most NLP models (BERT-Base/Large), recommendation systems, inference workloads
- Choose 32GB for: Larger NLP models (GPT-2, moderate LLMs), high-resolution image processing, molecular dynamics
Price Premium: 32GB variants cost 40-50% more than 16GB versions. Evaluate whether your models require the extra capacity before paying the premium.
6. Can H100 GPUs run older CUDA code written for V100?
Yes, with full backward compatibility. CUDA maintains forward compatibility, meaning:
Binary Compatibility:
- CUDA binaries compiled for V100 (Compute Capability 7.0) run on H100 (CC 9.0) without recompilation
- Performance will be suboptimal without leveraging H100-specific features
Source Compatibility:
- CUDA source code compiles for H100 without modifications
- Recompile with -arch=sm_90 to leverage H100 features
Optimization Recommendations:
- Recompile for H100 to enable architecture-specific optimizations
- Update to frameworks supporting FP8 and Transformer Engine
- Adjust batch sizes and hyperparameters for H100’s capabilities
What Won’t Work:
- Code specifically requiring H100 features (FP8, new Tensor Core operations) won’t run on V100
- This is typically only an issue if you develop on H100 then try to deploy on V100 (unusual workflow)
7. Should I buy GPUs or use cloud GPU services?
Decision Framework:
Choose Ownership (On-Premise) When:
- Utilization will exceed 60-70% consistently
- 3+ year deployment horizon with stable workload
- Data sovereignty or security requirements prevent cloud usage
- Predictable, steady workload (not bursty)
- Total compute requirements >20,000 GPU hours/year
ROI Break-Even: Typically 12-18 months of >60% utilization justifies ownership vs. cloud costs.
Choose Cloud (Cyfuture Cloud, etc.) When:
- Variable, unpredictable workload patterns
- Need to scale rapidly for specific projects
- Want to test different GPU generations before committing
- Insufficient capital for upfront hardware investment
- Prefer OpEx vs. CapEx accounting treatment
- Total compute requirements <20,000 GPU hours/year
Hybrid Approach: Many organizations optimize costs by:
- Owning baseline capacity (V100/A100) for steady-state workloads
- Using cloud burst capacity (H100) for peak demand and experimentation
- Migrating development/testing to cloud while keeping production on-premise
Cyfuture Cloud’s flexible contracts enable this hybrid strategy without long-term lock-in.
8. What’s the NVIDIA Tesla V100 vs NVIDIA GeForce RTX 4090 comparison?
This question often arises as the consumer RTX 4090 ($1,600) delivers impressive raw performance:
RTX 4090 Advantages:
- Much lower price ($1,600 vs $5,000+ for V100)
- Higher FP32 performance (83 TFLOPS vs 15.7)
- More memory bandwidth (1 TB/s vs 900 GB/s)
- Newer architecture (Ada Lovelace, 2022 vs Volta, 2017)
V100 Advantages:
- ECC memory (critical for scientific computing accuracy)
- Higher double-precision (FP64) performance (7.8 TFLOPS vs 1.3)
- Intended for 24/7 operation with better reliability
- NVLink support for multi-GPU configurations
- Data center thermal design and rack compatibility
- Enterprise drivers and longer support lifecycle
Bottom Line:
- For AI/ML training and inference: RTX 4090 offers better value
- For scientific HPC requiring FP64: V100 significantly better
- For production data center deployment: V100’s reliability and serviceability justify premium
- For multi-GPU setups: V100’s NVLink provides major advantages
Many researchers use RTX 4090 for development and V100/A100/H100 for production deployment.
9. How does Multi-Instance GPU (MIG) work on A100?
MIG enables GPU partitioning into up to 7 isolated instances, each with:
- Dedicated memory allocation
- Dedicated compute resources
- Hardware-level isolation (not just virtualization)
- Independent fault domains
Available MIG Profiles on A100 80GB:
- 1g.10gb: 7 instances, 10GB each
- 2g.20gb: 3 instances, 20GB each
- 3g.40gb: 2 instances, 40GB each
- 4g.40gb: 1 instance, 40GB
- 7g.80gb: 1 instance (full GPU)
Use Cases:
- Multi-tenancy: Serve 7 different users on single GPU
- Inference serving: Run 7 different models simultaneously
- Development: Provide isolated environments for developers
- CI/CD: Parallel test execution on single GPU
Limitations:
- Cannot dynamically resize instances without workload interruption
- Some configurations may not utilize 100% of GPU resources
- Not supported on V100 or H100 (H100 has MIG but with different profile options)
ROI Impact: Organizations report 2-3x improvement in GPU utilization (from 30-40% to 70-85%) by implementing MIG-based multi-tenancy.





















Stay Ahead of the Curve.
Join the Cloud Movement, today!
Send this to a friend