Get 69% Off on Cloud Hosting : Claim Your Offer Now!
- Products
- Solutions
-
Solutions
-
 Cloud
Hosting
Cloud
Hosting
-
VPS
Hosting
-
 GPU
Cloud
GPU
Cloud
-
 Dedicated
Server
Dedicated
Server
-
 Server
Colocation
Server
Colocation
-
 Backup as a Service
Backup as a Service
-
 CDN
Network
CDN
Network
-
 Window
Cloud Hosting
Window
Cloud Hosting
-
 Linux
Cloud Hosting
Linux
Cloud Hosting
-
Managed
Cloud Service
-
 Storage
as a Service
Storage
as a Service
-
VMware
Public Cloud
-
Multi-Cloud
Hosting
-
Cloud
Server Hosting
-
Bare
Metal Server
-
Virtual
Machine
-
 Magento
Hosting
Magento
Hosting
-
 Remote
Backup
Remote
Backup
-
 DevOps
DevOps
-
 Kubernetes
Kubernetes
-
 Cloud
Storage
Cloud
Storage
-
 NVMe
Hosting
NVMe
Hosting
-
 DR
as s Service
DR
as s Service
-
-
Solutions
- Marketplace
- Pricing
- Resources
- Company
 Pricing
Calculator
Pricing
Calculator
 Power
Power
 Utilities
Utilities VMware
Private Cloud
VMware
Private Cloud VMware
on AWS
VMware
on AWS VMware
on Azure
VMware
on Azure Service
Level Agreement
Service
Level Agreement Table of Contents
Introduction:
In the rapidly evolving domain of AI and high-performance computing (HPC), cutting-edge hardware plays a pivotal role in driving breakthroughs across industries. NVIDIA’s H100 GPU marks a significant milestone in this journey—engineered on the groundbreaking Hopper architecture, the H100 sets new standards in computational power, memory bandwidth, and AI acceleration. Tailored for tech leaders, enterprises, and developers invested in accelerating AI training, inference, and complex scientific workloads, the H100 promises transformative capabilities backed by the latest technologies and impressive metrics. This blog dives deep into the core technical innovations, performance benchmarks, and architectural enhancements that make the NVIDIA H100 one of the most powerful GPUs designed to date.
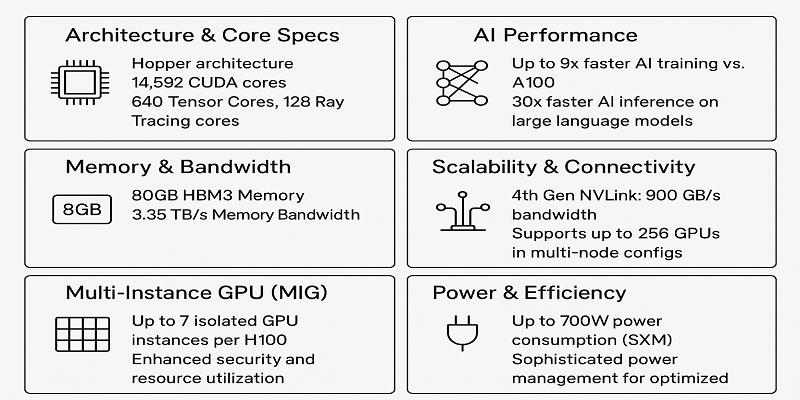
Core Technical Specifications and Innovations:
- Architecture: Built on NVIDIA’s Hopper architecture, the H100 GPU introduces fourth-generation Tensor Cores—a quantum leap in AI processing efficiency. It supports a rich variety of precision formats including FP64, FP32, TF32, FP16, BFLOAT16, FP8, and INT8, enabling versatile computation tailored to diverse AI models and HPC tasks.
- Tensor Cores: The H100’s Tensor Cores include the novel Transformer Engine optimized for transformer-based models, delivering up to 9x faster AI training and 30x faster AI inference on large language models compared to its predecessor, the A100.
- Compute Units: Featuring 14,592 CUDA cores, 640 Tensor Cores, and 128 Ray Tracing cores, the H100 achieves up to 67 TFLOPS of FP32 performance and 34 TFLOPS for FP64 precision, tripling the floating point throughput over previous GPUs.
- Memory: Equipped with 80GB of cutting-edge HBM3 memory running at 3.35 terabytes per second (TB/s) bandwidth, the H100 can handle massive datasets and large AI models with unprecedented speed and efficiency.
- NVLink & Scalability: The fourth-generation NVLink interconnect delivers 900 GB/s bandwidth for GPU-to-GPU communication, supporting direct scaling to 256 GPUs with low latency, a critical advantage for distributed training and HPC clusters.
- Multi-Instance GPU (MIG): The second-generation MIG technology allows the H100 to partition a single GPU into up to 7 secure and isolated GPU instances, each with dedicated compute and memory resources to maximize utilization in multi-tenant or cloud environments.
- Power & Efficiency: The SXM form factor of the H100 consumes up to 700 watts, incorporating advanced power management to optimize energy efficiency relative to workload demands.
Performance Impact and Use Cases:
The H100 is designed for large-scale AI model Library training and inference workloads, scientific simulations, data analytics, and enterprise AI applications. Its combination of FP8 precision and the Transformer Engine enables it to accelerate transformer-based neural networks dramatically, a critical factor for next-generation large language models and conversational AI systems. The extensive memory bandwidth and multi-GPU scalability make it ideal for handling complex HPC tasks and massive data sets efficiently.

Conclusion:
The NVIDIA H100 GPU exemplifies the forefront of Cloud GPU hosting technology engineered for the most demanding AI and HPC workloads today. Its groundbreaking architecture, massive computational power, expansive memory bandwidth, and finely tuned scalability capabilities make it a vital platform for enterprises and developers focused on pioneering AI innovation, scientific breakthroughs, and data-driven insights with efficiency. As organizations increasingly leverage AI and high-precision computing, integrating the NVIDIA H100 will be pivotal in transforming how large-scale computation and AI models evolve in the cloud era.
If you seek to harness the future of AI infrastructure, the NVIDIA H100 GPU offers unmatched capabilities to power your next generation of computing challenges.
Recent Post




















Stay Ahead of the Curve.
Join the Cloud Movement, today!
Send this to a friend