Get 69% Off on Cloud Hosting : Claim Your Offer Now!
- Products
- Solutions
-
Solutions
-
 Cloud
Hosting
Cloud
Hosting
-
VPS
Hosting
-
 GPU
Cloud
GPU
Cloud
-
 Dedicated
Server
Dedicated
Server
-
 Server
Colocation
Server
Colocation
-
 Backup as a Service
Backup as a Service
-
 CDN
Network
CDN
Network
-
 Window
Cloud Hosting
Window
Cloud Hosting
-
 Linux
Cloud Hosting
Linux
Cloud Hosting
-
Managed
Cloud Service
-
 Storage
as a Service
Storage
as a Service
-
VMware
Public Cloud
-
Multi-Cloud
Hosting
-
Cloud
Server Hosting
-
Bare
Metal Server
-
Virtual
Machine
-
 Magento
Hosting
Magento
Hosting
-
 Remote
Backup
Remote
Backup
-
 DevOps
DevOps
-
 Kubernetes
Kubernetes
-
 Cloud
Storage
Cloud
Storage
-
 NVMe
Hosting
NVMe
Hosting
-
 DR
as s Service
DR
as s Service
-
-
Solutions
- Marketplace
- Pricing
- Resources
- Company
 Pricing
Calculator
Pricing
Calculator
 Power
Power
 Utilities
Utilities VMware
Private Cloud
VMware
Private Cloud VMware
on AWS
VMware
on AWS VMware
on Azure
VMware
on Azure Service
Level Agreement
Service
Level Agreement Table of Contents
With the rapidly increasing volume of data generated by businesses, the need for data management and analysis tools becomes more important.
In this blog, we introduce a continuously growing software-as-a-service (SaaS) platform, Databricks. Databricks is a popular cloud-based platform for data management, analysis, and collaboration.
What does Databricks do? Databricks provides a unified analytics platform that simplifies data engineering, data science, and machine learning tasks, allowing teams to collaborate seamlessly on big data projects. It offers robust tools for processing and analyzing large datasets, along with powerful machine-learning capabilities.
We go over exactly what it is—how it works—what it is used for—its benefits, features, and other related details.
Let’s get started!
Databricks: An Introduction
Databricks is a single, cloud-based platform that can handle all of your data needs. It provides a unified workspace for data engineers, data scientists, and business analysts to work collaboratively on big data, data processing, visualization, and machine learning projects. This means it is a single platform where your entire data team can collaborate.
|
Did You Know? Databricks was founded in 2013 by Apache Spark, this widely used open-source distributed computing engine for large-scale data processing. It is fast, cost-effective and inherently scales to very large data. |
Databricks can be used to process and analyze data stored in data lakes, making it a powerful tool for working with these types of repositories.
It supports a range of programming languages including Python, R, SQL, and Scala. Databricks also provides an easy-to-use web-based user interface, which allows users to write code, visualize data, and collaborate with team members.
It is available on top of your existing cloud, whether that’s AWS, Microsoft Azure, GCP, or even a multi-cloud combination of those.
How do Databricks work?
Databricks is a powerful distributed computing engine that allows users to process large-scale data. Spark provides a unified API for data processing, which allows users to write code in multiple languages, including Python, R, SQL, and Scala.
Databricks provides a cloud-based environment for data processing, machine learning, and visualization.
Databricks platform offers two main components: Databricks Workspace and Databricks Runtime.
Databricks Workspace
Databricks Workspace is a web-based user interface that provides an integrated environment for data processing, machine learning, and collaboration. It allows users to write code in multiple languages and provides a range of tools for data visualization, exploration, and collaboration.
The workspace provides a notebook interface, which allows users to write and execute code in an interactive environment. Notebooks are organized into folders, which can be shared with team members. The workspace also provides a range of tools for version control, collaboration, and data visualization.
Databricks Runtime
Databricks Runtime is a cloud-based platform that provides a unified environment for data processing and machine learning. It includes Apache Spark, as well as a range of pre-installed libraries and tools for data processing, machine learning, and visualization.
Databricks Runtime provides a range of options for data processing, including batch processing, streaming, and machine learning. It supports a range of data sources, including structured, semi-structured, and unstructured data. The platform also includes a range of tools for data exploration, feature engineering, and model training.

What is Databricks used for?
Databricks has become an essential tool for data scientists and engineers for several reasons:
Scalability
Databricks is built on top of Apache Spark, which allows users to process large-scale data. Spark provides a unified API for data processing, which allows users to write code in multiple languages, including Python, R, SQL, and Scala. Databricks Runtime provides a range of options for data processing, including batch processing, streaming, and machine learning.
Collaboration
Databricks Workspace provides a web-based user interface that allows users to collaborate on big data and machine learning projects. The workspace provides a notebook interface, which allows users to write and execute code in an interactive environment. Notebooks are organized into folders, which can be shared with team members. The workspace also provides a range of tools for version control, collaboration, and data visualization.
Integration
Databricks supports a range of data sources, including structured, semi-structured, and unstructured data. The platform also includes a range of tools for data exploration, feature engineering, and model training. Databricks integrates with a range of third-party tools, including data storage platforms, such as Amazon S3 and Azure Blob Storage, and data visualization tools, such as Tableau and Power BI.
Ease of use
Databricks provides an easy-to-use web-based user interface, which allows users to write code, visualize data, and collaborate with team members. The platform also provides a range of pre-installed libraries and tools for data processing, machine learning, and visualization.
Cost-effective
Databricks offers a pay-as-you-go pricing model, which allows users to pay only for the resources they use. The platform also provides a range of pricing tiers, which allows users to choose the plan that best fits their needs.
Databricks Architecture
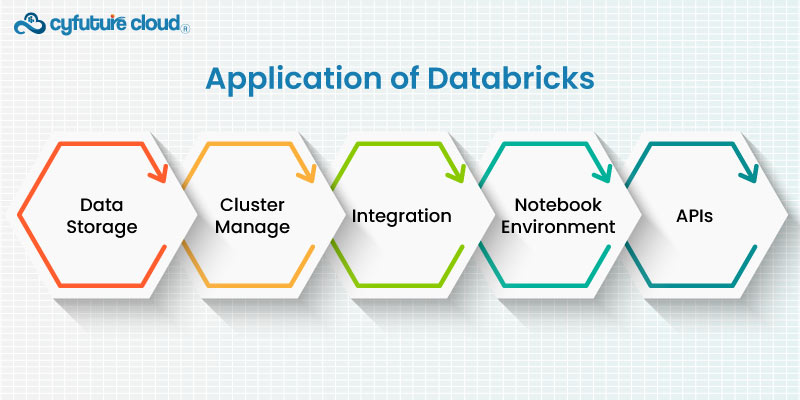
Databricks architecture is designed to provide a scalable and reliable platform for big data processing and machine learning. The architecture is based on the concept of a cluster, which is a group of computing resources that work together to process data. In this section, we will discuss the key components of the Databricks architecture.
Cluster Manager
The cluster manager is the central component of the Databricks architecture. It is responsible for managing the computing resources used by Databricks clusters. The cluster manager can automatically provision and manage the resources required to process data, such as CPU, memory, and storage. It can also scale the cluster up or down based on the workload.
Databricks Runtime
Databricks Runtime is a pre-configured environment that provides a range of pre-installed libraries and tools for data processing, machine learning, and visualization. The runtime includes Apache Spark, Delta Lake, and Structured Streaming, which allow users to process large-scale data efficiently. The runtime also includes a range of machine learning libraries, such as TensorFlow, PyTorch, and sci-kit-learn.
Notebook Environment
The Notebook environment is a web-based interface that allows users to write and run code on the Databricks platform. Notebooks are used to write code, visualize data, and collaborate with team members. The Notebook environment provides support for a range of programming languages, including Python, R, SQL, and Scala.
Data Storage
Databricks supports a range of data storage options, including Databricks File System (DBFS), Amazon S3, Azure Blob Storage, and Hadoop Distributed File System (HDFS). Users can store their data in a centralized location and process it using the Databricks platform.
APIs
Databricks provides APIs for data processing, machine learning, and collaboration. Users can interact with the Databricks platform using APIs to automate tasks, build custom integrations, and perform advanced analytics.
Security
Databricks provides a range of security features to ensure the security of user data. The platform supports encryption at rest and in transit, role-based access control, and multi-factor authentication. Databricks is also compliant with a range of industry standards, such as SOC 2, HIPAA, and GDPR.
key Components of Databricks Architecture
| Databricks Architecture Components | Description |
|---|---|
| Workspace | Collaborative environment allowing users to manage notebooks, libraries, and data, facilitating teamwork and version control for code and analysis. |
| Apache Spark | Core engine for distributed data processing, enabling data manipulation, analysis, and machine learning tasks within Databricks’ unified analytics platform. |
| Jobs | Automated tasks or workflows for executing code or notebooks at specified intervals or events, enabling scheduling and automation of data processes. |
| Clusters | Virtual machines managed by Databricks to execute Spark jobs, providing scalable and customizable compute resources for data processing tasks. |
| Data Lake Integration | Connectivity and integration with various data lakes (e.g., AWS S3, Azure Data Lake Storage) for seamless data ingestion and processing within Databricks. |
| MLflow | Built-in platform for managing machine learning lifecycle, allowing tracking experiments, packaging code, and deploying models for production use. |
Conclusion
Databricks is a cloud-based platform for data management, analysis, and collaboration. It provides an integrated environment for data processing, machine learning, and visualization, and is built on top of Apache Spark. Databricks have become an essential tool for data scientists and engineers due to their scalability, collaboration features, integration with third-party tools, ease of use, and cost-effectiveness.
Databricks can be used in a range of use cases, including data processing, machine learning, data visualization, and collaborative projects. If you are looking for a powerful cloud-based platform for big data and machine learning projects, Databricks is definitely worth considering.
Recent Post





















Stay Ahead of the Curve.
Join the Cloud Movement, today!
Send this to a friend