CYFUTURE AI: DRIVING DIGITAL TRANSFORMATION SOLUTIONS
INTRODUCTION TO CYFUTURE AI

Cyfuture AI is at the forefront of technological advancement, committed to revolutionizing how businesses operate in the digital landscape. With a strong foothold in both India and international markets, Cyfuture specializes in a spectrum of core services, focusing on cloud solutions, AI applications, and business process services. The company's mission is to assist organizations in adapting to the evolving demands of the digital era, positioning them for success in a competitive marketplace.
CORE SERVICES
Cyfuture AI offers a comprehensive suite of services that empower businesses to enhance their operational efficiency and innovation capabilities:
- Cloud Solutions: Reliable and scalable, Cyfuture's cloud infrastructure supports businesses in managing their computing and storage needs securely.
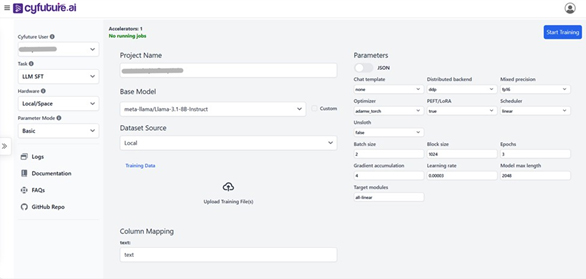
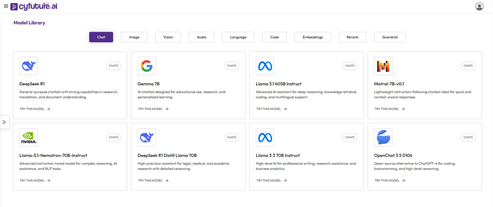
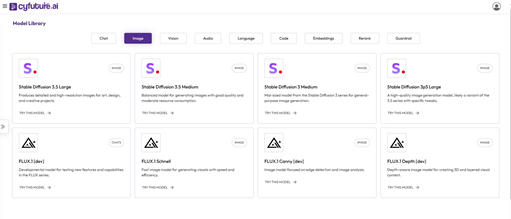
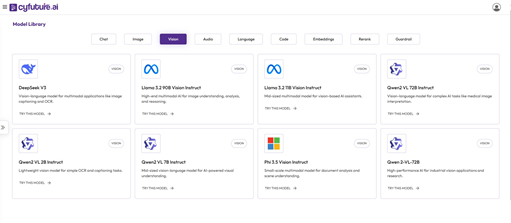
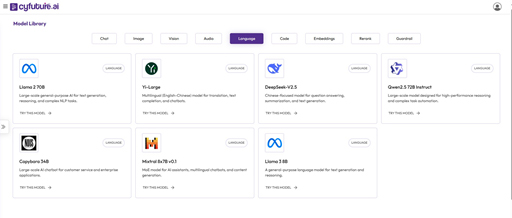
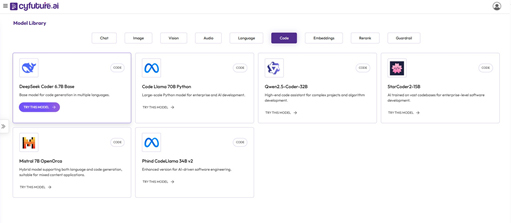
- AI Capabilities: With advanced technologies, including machine learning, natural language processing (NLP), computer vision, and predictive analytics, Cyfuture enables organizations to automate processes, gain actionable insights, and make informed decisions.
- Business Process Services: Tailored solutions are provided to help optimize workflows, ensuring that businesses can focus on core competencies while Cyfuture manages essential processes.
SIGNIFICANCE IN TODAY'S TECHNOLOGICAL LANDSCAPE
In an era where data is pivotal for strategic decision-making, Cyfuture's AI integration facilitates not only operational improvements but also significant competitive advantages. Industries, including healthcare, finance, manufacturing, and telecommunications, benefit from these transformative technologies, ensuring they remain agile and responsive to market demands.
COMMITMENT TO INNOVATION
Cyfuture AI's dedication to innovation is evident through its continual investment in cutting-edge technology. By focusing on digital transformation, the company empowers businesses to harness AI's full potential, enhancing productivity and positioning them for future growth. With multiple Tier III data centers ensuring secure and reliable hosting, Cyfuture is uniquely equipped to support businesses in their journey toward a smarter, more connected future.
COMPANY OVERVIEW
Founded with a vision to reshape the technology landscape, Cyfuture AI has emerged as a leader in providing comprehensive solutions that facilitate the digital transformation of businesses. The company's journey began with a focus on harnessing emerging technologies to address the evolving needs of various industries. As a result, Cyfuture has established itself as a trusted partner for organizations seeking to improve their operational capabilities through innovative technology.
VISION AND MISSION
Cyfuture AI's mission revolves around enabling organizations to thrive in an increasingly digital-centric world. The company's vision is to be a catalyst for change, helping businesses transition seamlessly into the digital era. By prioritizing customer-centric solutions, Cyfuture aims to empower clients with the tools needed to achieve sustainable growth and operational excellence.
KEY AREAS OF SPECIALIZATION
These core areas showcase the company's commitment to delivering integrated solutions that address the full spectrum of challenges faced by modern organizations. With a strong operational presence in India, Cyfuture AI has expanded its footprint to international markets, reflecting the company's ambition to support digital transformation on a global scale. The firm recognizes that the journey toward integration of technology is not uniform across regions; therefore, it tailors its offerings to meet the specific business environments and regulatory frameworks of various countries. In today's digital landscape, organizations must adapt rapidly to changing market dynamics and consumer expectations. Cyfuture AI's suite of services is meticulously designed to respond to these pressures. By providing cutting- edge cloud and infrastructure solutions, as well as effective business process management, Cyfuture empowers its clients to improve efficiency, reduce costs, and accelerate time-to-market for their products and services. In conclusion, Cyfuture AI stands out as a pioneer in driving digital transformation across various sectors, ensuring organizations are equipped with the necessary technological foundations to succeed in a competitive environment. Cyfuture's AI Platform is a cornerstone of its service offering, providing businesses with advanced, integrated capabilities that are essential for navigating today’s digital era. This platform harnesses a suite of powerful technologies, including machine learning, natural language processing (NLP), and speech recognition. Each of these features is designed to enhance operational efficiency, automate processes, and foster better decision- making. With the integration of these AI capabilities, businesses can automate routine tasks, extract valuable insights from massive datasets, and foster data-driven decision-making. The AI Cloud Platform not only supports operational excellence but also positions organizations to be more agile and competitive in their respective industries. By using Cyfuture’s AI Cloud Platform, companies gain a strategic partner ready to empower them with necessary tools for success in a rapidly evolving digital landscape. In the contemporary business environment, scalable and secure AI solutions are paramount for organizations striving to maintain a competitive edge. The rapid evolution of technology, paired with an exponential increase in data generation, necessitates that businesses implement flexible and secure infrastructures capable of embracing growth and managing information responsibly. Scalability allows businesses to expand their operations without disrupting existing processes. Cyfuture AI's cloud solutions are engineered for scalability, ensuring that organizations can swiftly adjust their computing and storage resources according to fluctuating demands. This capability is essential, particularly for industries such as retail, where seasonal peaks can dramatically affect data storage and processing needs. Equally important is the aspect of security. In a world where cyber threats are increasingly sophisticated, businesses must prioritize the protection of their sensitive data alongside scalability. Cyfuture integrates robust security protocols and infrastructure in all its AI solutions, utilizing encryption, comprehensive firewalls, and regular security audits. This commitment to maintaining high security standards instills confidence in organizations, allowing them to focus on their core competencies without unnecessary worry about data breaches. The versatility of Cyfuture's AI solutions allows for customization across multiple industries, ensuring that specific operational needs and regulatory requirements are met. Here are some examples: The versatility of Cyfuture's AI solutions allows for customization across multiple industries, ensuring that specific operational needs and regulatory requirements are met. Here are some examples: Finance: Financial institutions require solutions that not only enhance operational efficiency but also adhere to stringent regulatory standards. Cyfuture's AI capabilities in this sector help organizations identify fraudulent activities in real time while ensuring that all customer data remains secure. Retail: Retail businesses benefit from AI solutions that optimize inventory management and improve customer experience. By implementing machine learning algorithms, retailers can accurately predict customer purchasing patterns, allowing them to adjust supply chains effectively while maintaining strict data privacy standards. Manufacturing: In manufacturing, predictive maintenance powered by AI can significantly reduce downtime. Cyfuture’s solutions enable manufacturers to predict equipment failures, streamlining operations without compromising the security of their sensitive production data. Telecommunications: Telecommunications companies utilize Cyfuture's scalable AI solutions to enhance customer service and reduce churn rates. Implementing natural language processing tools allows for improved interaction tracking and automated customer support systems while ensuring that data remains protected. Cyfuture AI's infrastructure is built around its state-of-the-art Tier III data centers strategically located in India. These data centers are a crucial asset for ensuring that businesses receive reliable, scalable cloud services tailored to their specific needs. Here's a closer look at the features and benefits of Cyfuture's data center offerings: Tier III Standards: Cyfuture's data centers meet Tier III standards, implying an availability of 99.982%. This level of uptime is critical for businesses that rely on continuous access to their data and applications. Redundancy: Each data center is designed with redundancy across all systems including power, cooling, and network connectivity. This design approach minimizes the risk of outages and ensures operational continuity even in unexpected scenarios. Robust Security Protocols: Data security is paramount at Cyfuture. The data centers utilize cutting-edge security protocols including: Compliance with Standards: Cyfuture adheres to global security and privacy standards, such as ISO 27001, ensuring data integrity and compliance with regulations across sectors. Elasticity of Resources: With scalable cloud services, businesses can dynamically adjust their computational and storage resources to match real- time demands. This flexibility is especially beneficial during peak seasons or unexpected surges in data usage, allowing organizations to optimize their costs. Support for Diverse Applications: Whether for large-scale enterprise applications or smaller projects, the scalability of Cyfuture's infrastructure accommodates various workloads efficiently, providing clients with the necessary resources to thrive. Improved Performance: With high reliability and security, organizations can operate confidently, knowing their data is safe and accessible, thus enhancing overall productivity. Enhanced Data Management: Businesses benefit from advanced data management capabilities that stem from robust infrastructure, facilitating better decision-making and strategic planning. Fostering Innovation: A reliable infrastructure allows businesses to focus on innovation rather than IT issues, enabling them to launch new products and adapt to changing market conditions swiftly. Overall, Cyfuture's Tier III data centers form the backbone of its services, playing an integral role in supporting organizations across various industries
with scalable, secure, and efficient cloud infrastructure that meets the demands of today's digital landscape.
Cyfuture is steadfast in its commitment to maintaining high-quality service delivery, validated through several prestigious certifications that reflect compliance with international standards. Two key certifications held by Cyfuture include ISO 20000-1:2018 and ANSI/TIA-942. Cyfuture AI's comprehensive service portfolio encompasses technology, management, and consulting services tailored to help organizations adapt to
the ever-evolving digital landscape. By integrating innovative technologies, Cyfuture empowers businesses to drive operational efficiency, optimize resource management, and enhance competitive advantage in their respective sectors.
The technology services offered by Cyfuture include: Cyfuture's management services focus on streamlining and optimizing business processes to increase efficiency. Key offerings include: With a strong emphasis on strategic consulting, Cyfuture assists organizations in navigating their digital transformation journeys. Their consulting services include: Several notable engagements highlight the effectiveness of Cyfuture's services: Retail Industry: A leading retail chain used Cyfuture's consulting services to revamp its inventory management system. This not only reduced waste but also increased customer satisfaction through better product availability. These examples illustrate how Cyfuture's diverse service portfolio not only meets but exceeds client expectations, empowering organizations to innovate and thrive in a highly competitive environment. Cyfuture AI is resolutely committed to integrating artificial intelligence (AI) and other emerging technologies to drive operational efficiency and foster innovation. This dedication enables organizations to enhance their competitiveness in an ever-evolving marketplace. The company continuously invests in research and development to harness cutting-edge technologies. By implementing AI solutions, Cyfuture helps businesses automate mundane tasks, allowing teams to focus on strategic initiatives and creative problem-solving. Such enhancements lead to quicker decision-making processes and improved productivity across various operational levels. Cyfuture is focusing on key future trends, such as: AI and Machine Learning: Developing more sophisticated algorithms that adapt to changing data patterns, ensuring businesses remain ahead of the curve. Internet of Things (IoT): Leveraging IoT technology to facilitate real-time data collection and analysis, enriching customer experiences and operational management. Blockchain: Exploring blockchain for secure and transparent transactions, particularly in industries where traceability and trust are paramount. By staying at the forefront of these technological advancements, Cyfuture prepares its clients for future challenges, solidifying its position as a trusted partner in digital transformation across various sectors.
OPERATIONS IN INDIA AND INTERNATIONAL MARKETS
MEETING MODERN DEMANDS
KEY FEATURES
USE CASES
ENHANCING DECISION-MAKING
IMPORTANCE OF SCALABILITY
ENSURING SECURITY
TAILORED SOLUTIONS FOR VARIOUS INDUSTRIES

RELIABILITY AND UPTIME
DATA SECURITY
SCALABILITY AND CLOUD SERVICES
ADVANTAGES FOR BUSINESS OPERATIONS
CERTIFICATIONS AND STANDARDS
TECHNOLOGY SERVICES
MANAGEMENT SERVICES
CONSULTING SERVICES
ENHANCING EFFICIENCY AND INNOVATION
FUTURE TECHNOLOGY TRENDS