




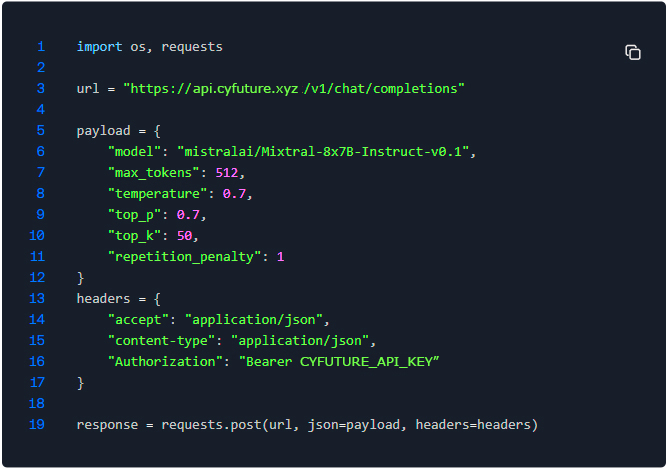



Why Cyfuture AI Stands Out
We've engineered a high-performance AI inference platform designed for seamless deployment, effortless scaling, and cost efficiency.
01
Seamless Deployment
Deploy AI models consistently across applications, frameworks, and platforms with ease, powered by our robust Inferencing as a Service solution.
02
Effortless Integration & Scaling
Integrate smoothly with public clouds, on-premise data centers, and edge computing environments, ensuring flexibility for your AI Inference as a Service needs.
03
Optimized Cost Efficiency
Maximize AI infrastructure utilization and throughput with our Inferencing as a Service platform, reducing operational costs without compromising performance.
04
Unmatched Performance
Leverage cutting-edge AI performance to push the boundaries of innovation.



